2026
During conscious learning, observers prioritize which aspects of the input to learn in an efficient, goal-directed manner. Statistical learning (SL) unconsciously extracts and represents patterns of individual elements, or “chunks,” from the environment. However, it remains unknown whether this automatic processing also follows a biased learning strategy, as higher-level learning does.
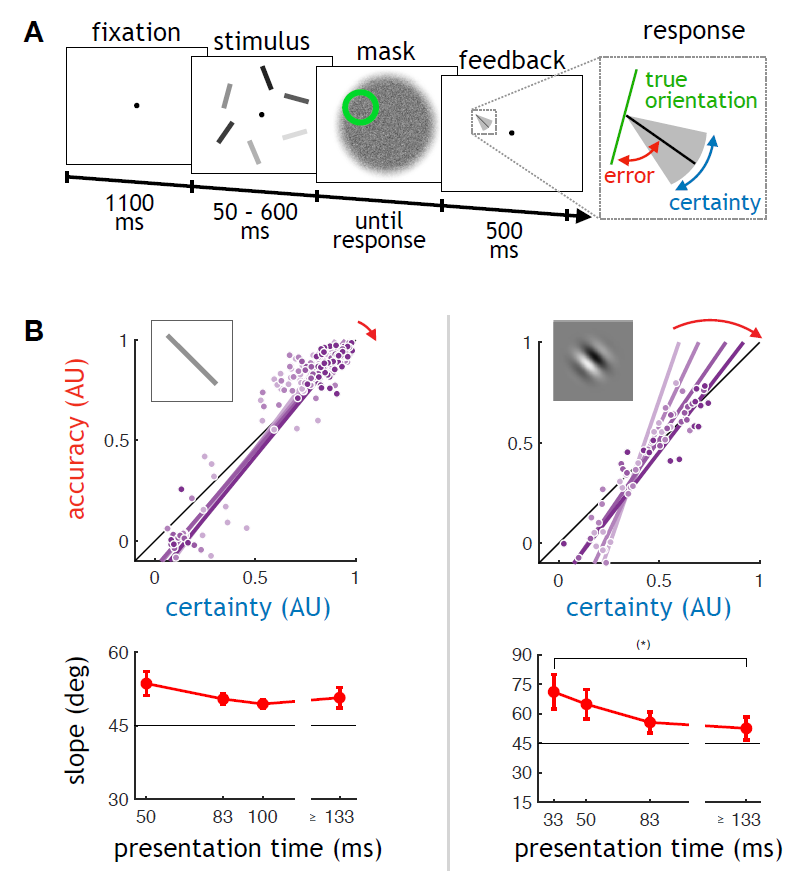
We hypothesized the existence of general chunking principles in SL that operate at the lowest perceptual level across sensory attributes and modalities when extracting statistical regularities. To test this, we relied on the Iambic–Trochaic Law (ITL), which posits that in auditory sequences, an element with longer duration signals the end of a segment to the observer, leading to decreased accuracy in detecting perceptual changes at segment boundaries.
We implemented the same stream-segregation paradigm in audition and vision to explore the generality of the ITL. Simple tones or basic visual objects of 200 ms and 600 ms duration were presented in a stream of three-element repeating pattern in a go/no-go paradigm with the task of detecting changes in gap duration. Participants exhibited similar boundary-related sensitivity changes in both modalities, confirming the “longer-last” principle. These findings suggest modality-independent duration-based chunking mechanisms.
Efficient coding is a widely established principle for how the brain allocates sensory resources in order to improve the encoding of perceptual (and other) variables. Typically, efficient coding assumes adaptation to long-run statistics of the environment. Yet, evidence suggests the brain also adapts efficiently and near-instantaneously to rapid changes in stimulus statistics. Here, to unify efficient coding at different time scales, we develop a model of context-dependent efficient coding (CoDEC) that combines previously suggested principles of Bayesian efficient coding and contextual inference. According to CoDEC, the brain uses trial-by-trial contextual inference to identify the current task context, which in turn guides the gradual refinement of context-dependent stimulus statistics on long time scales. Crucially, CoDEC learns the transition structure between task contexts from the training curriculum. Using this structure, CoDEC performs dynamical contextual inference to control both resource allocation through efficient coding (based on the learned stimulus distributions of each previously encountered context and their respective inferred probabilities in the current trial) and the updating of context-dependent stimulus distributions. We show that CoDEC accounts for a range of seemingly contradicting results from “roving” paradigms that revealed a strong dependence of perceptual learning (PL) on task structure, which have been difficult to reconcile with canonical, feed-forward “reweighting”-based models of PL. Beyond replicating classical PL and capturing all previously reported roving effects, CoDEC also makes novel predictions about the existence of “latent learning” under a random roving training curriculum that can be rapidly unmasked by introducing predictability during testing. By putting context-dependence center stage, CoDEC highlights the importance of feedback, as opposed to purely feed-forward, neural mechanisms of efficient coding and PL.
Perceptual decisions and eye movements are shaped by sensory information and expectations about the environment, reflecting experience-dependent internal models. Yet, they do not always adapt to context in the same way, suggesting they may rely on partly different internal representations.
In direction-biased motion tasks, anticipatory eye movements track the most frequent direction while perceptual discrimination is sometimes biased toward the least frequent one. Less is known about visually-guided eye movements. Here we ask whether perception and eye movements rely on a shared representation of context in a direction-biased random dot kinematogram (RDK) task, or distinct computational strategies.
Thirteen observers (N = 13) performed a direction discrimination task in two conditions, reporting leftward or rightward motion in an RDK in a 2-AFC decision-making paradigm, while eye movements were recorded. The experiment comprised two phases: an adaptive staircase to estimate RDK direction discrimination thresholds, followed by a main task in which motion coherence varied randomly across trials. Crucially, motion direction probabilities shifted from unbiased (50/50) to biased (80/20), either abruptly (JUMP) or gradually (RAMP).
In the JUMP condition, perceptual decisions were robustly biased toward the less frequent direction, a counterintuitive effect that persisted across trials and replicated prior findings, including an independent online experiment (N = 24). This deviates from normative predictions that favor the more frequent direction. Anticipatory eye movements were instead biased toward the more frequent direction, as was early visually guided smooth pursuit, though the latter appeared primarily driven by recent trial history with no clear influence of global probability. In the RAMP condition, the same pattern of oculomotor adaptation was observed, whereas the perceptual bias toward the less frequent direction was reduced, though it remained present. Together, these preliminary findings suggest a partial dissociation between perceptual and oculomotor processes, potentially governed by distinct internal representations of probabilistic context.
Statistical learning involves extracting regularities of token appearances, and inferring the underlying abstract structure governing pattern formation. In graph-learning tasks, this structure corresponds to the rules defining transitions within the graph. The acquired structural knowledge should enable transfer across environments sharing the same organization but differing in observable tokens. A key question is whether individuals who learn faster within graphs also show stronger transfer across graphs, or learning rate and transfer reflect independent components of behavior.
We reanalyzed the graph-learning dataset of Mark et al. (eLife, 2024), focusing on the graphs that shared hexagonal grid structure. Within days, graphs had identical structure but different tokens labeling the states, whereas across days they were variants of the grid structure. Accuracy across blocks within each graph was analyzed using a hierarchical Bayesian model separating baseline performance, within-graph learning, and graph-specific shifts.
Transfer appeared primarily as performance shifts across graphs rather than changes in learning rate. Shifts were largest across days, whereas within-day transitions were smaller and positively correlated across participants, suggesting stable individual differences in benefiting from prior experience with the exact same structure. Transfer effects overall showed little relation to learning rate, consistent with learning and transfer reflecting distinct behavioral components.
Chunking through statistical learning reportedly biases memory for features of chunked items toward each other. We examined how this bias depends on the strength and consistency of participants’ internal representations.
Across two experiments, participants completed a familiarization phase in which they uncovered hidden target objects in a grid based on a cue object. Cue–target pairs followed unknown spatial pairings with 100%, 80%, and 0% predictability in the Perfect, Partial, and Random conditions, respectively. On each trial, object colours were sampled from unique, object-specific distributions. Familiarization consisted of object–cue pairs with either Perfect and Partial (Exp1, N=20) or Perfect and Random structures (Exp2, N=18), presented in intermixed trials.Following familiarization, participants provided four estimates of each object’s typical colour, yielding two measures: deviation from the distribution mean (precision) and response variance (consistency).
Memory bias toward the paired colour emerged only in low-consistency estimates for Perfect and Random stimuli. High-consistency reports clustered around the true colour mean, suggesting that previously reported biases arise primarily from less precise representations. In contrast, consistent reports for Partial stimuli were biased away from the paired colour, whereas less consistent reports centred on the true mean, indicating that rule violations modify chunked item representations.
Visual Statistical Learning (VSL) is typically investigated in isolation as either spatial or temporal learning, leaving open how these regularities interact when they co-occur in natural environments. Yet outside the laboratory, regularities unfold jointly across space and time and must be interpreted in context. Using a novel spatio-temporal paradigm in which spatially defined patterns dynamically moved in and out of view, with or without occluding elements, we examined how visual learning constructs structured internal descriptions from jointly available regularities.
We first replicated canonical spatial and temporal VSL effects within this integrated design. Crucially, learning reflected seamless integration of spatial and temporal statistics: behavior could not be explained by a simple additive combination of independent co-occurrence computations. Purely temporal regularities supported the construction of spatial structure, indicating cross-domain synthesis rather than parallel tracking. Moreover, motion-defined context and occlusion cues systematically shaped which regularities were learned from identical input, demonstrating that higher-level contextual biases are incorporated into the learning process in an equally integrated, non-linear manner.
Together, these findings reconceptualize VSL not as a passive recorder of isolated co-occurrences, but as a generative, interpretative process that selectively integrates spatio-temporal regularities with contextual biases to infer the latent structure of the environment.
The conjunction fallacy is a well-known breakdown of Bayesian reasoning, but its cognitive roots remain unclear. Most studies rely on ambiguous, story-based vignettes that leave room for interpretation. Less is known about its emergence in simpler, perception-based tasks with tightly controlled visual stimuli. We aim to explore this gap in two controlled experiments. In Experiment 1, we tested how people learn probabilistic rules involving abstract visual features in a continuous stream. Participants (N = 41) judged the probability of individual and combined features, as in traditional conjunction-error tasks. Individuals could identify typical features for trial types with specific traits, suggesting that representativeness was learned. Conjunction errors were rare; moreover, varying the representativeness of a feature did not significantly affect the fallacy rate, even though representativeness has been argued to be the leading cause of the fallacy. In Experiment 2, we used a more complex stimulus space defined by color, shape, and pattern. Participants (N=56) estimated single and combined feature probabilities using ranking or slider methods. Error rates similar to those observed in the original tasks emerged only under high comparison load, when multiple statements were ranked simultaneously or when participants had to maintain earlier estimates to stay consistent. However, when participants assessed a single conjunction and its constituent, fallacy rates dropped. Task order also had a significant effect: starting with the probability assessment lowered fallacy rates in the sorting task. Together, these experiments offer new insights into the conjunction fallacy in perception-based learning tasks. We found that the conjunction errors in perceptual tasks arise less from representativeness per se and more from constraints imposed by task structure. These findings support the theory of bounded rationality and show that fallacy rates can be reduced by presenting information in a visual sequence, thus reducing cognitive load.
Every conscious and involuntary action we make is strongly influenced by our internal model of the monetary environment and by the actual context. In our previous investigation of perceptual decision-making, we used response biases to identify which alternative internal representation observers used during their decisions. We found that, depending on the representation they adopted, observers could make opposite choices and, in particular, could follow decisions that appear irrational from the standpoint of a “standard” internal representation. In the present study, we explored whether the internal representation that sets the bias of conscious decisions also controls anticipatory eye movements, or conscious and involuntary actions are governed by different internal models. We used a modified version of the standard 2-AFC decision-making paradigm in which observers (N = 20) judged the direction of random-dot kinetograms moving either right or left. First, we identified each observer’s direction-sensitivity threshold with an adaptive staircase method, and then, in the main phase of the experiment, we used randomly chosen coherence levels on each trial. Importantly, when transitioning from threshold measurement to randomized trials, we also changed the appearance probability of the right/left motion directions from 50/50% to 80/20%, thereby imposing a general bias in the probability of motion across trials. Confirming our earlier results from a shape-classification task, observers’ decisions under these conditions showed a strong bias toward selecting the less frequent direction during low-coherence trials. This decision bias is long-lasting (over hundreds of trials) and contradicts the common expectation that observers should choose the more frequent direction. In contrast, measurements of anticipatory eye movements showed a significantly stronger bias toward the more frequent direction. Thus, the internal representations governing conscious decisions and the mechanisms of eye-movement control are at least partially dissociable. This work was supported by Grant ANR-FWF I 6793-B
The brain relies on various internally generated categories and stereotypes, formed through biased processing of inputs, to make rapid predictions. We investigated the hypothesis that applying such biases -identifying and focusing on particular groups and patterns that prioritize fast, goal-relevant efficiency over veridical accuracy- is not limited to higher-order cognitive processes. Instead, this strategy is applied automatically and recursively from the earliest levels of sensory processing. We focused on identifying basic chunking principles in the visual and auditory modalities. Behaviorally, chunking consistently leads to decreased accuracy in detecting perceptual changes at perceived chunk boundaries compared to changes within a segment. Using this measure in stimulus sequences with increasing internal structure across different modalities, we tested whether automatically applied temporal grouping principles are shared across vision and audition. We implemented a stream-segregation paradigm in which we manipulated the duration structure of the elements: 200- and 600-ms simple tones or basic visual objects were presented in a continuously repeating three-element pattern, such as Short–Short– Long or Short–Long–Long. Our results (N = 35) show that (1) participants exhibit similar sensitivity patterns across modalities: as soon as a repeating pattern emerges, sensitivity to environmental changes becomes biased by the same chunking principles. Boundaries in both modalities are marked by longer-duration sensory objects that function as closing elements; (2) this bias is automatic and often consciously unavailable to participants, even when attention is directed toward the stream; and (3) this pattern representation is highly resilient to absolute changes in element duration, as long as the relative duration supports a consistent repeating pattern. These results suggest that the perceptual system organizes sequences of elements with varying absolute durations into chains of tokens based on rapidly formed categories that remain remarkably stable even in noisy environments.
2025
At each level of abstraction, the brain performs the same operation: transforming the incoming information by chunking and extracting patterns to obtain more adequate and efficient representations that can support its goals. Despite the prevalence of such processes across sensory modalities, investigations into the organizing principles of segmentation (chunking) typically focus on individual modalities separately. We hypothesize that at least some basic chunking principles and corresponding perceptual biases are akin across modalities with tractable neural correlates in the primary sensory cortical areas.
To test this hypothesis, we focused on the auditory segmentation principle called the Iambic-Trochaic law (ITL). Established in language processing, ITL posits that longer syllables in a sequence signal word-ends while an increase in intensity signals the beginning of a word. Moreover, as a behavioral relevance, such chunking leads to decreased accuracy in detecting perceptual changes at perceived chunk boundaries compared to that within the segment itself.
Importantly, ITL biases have been found unrelated to linguistic content and across multiple species, but never tested in other modalities, we implemented a stream segregation go/no-go paradigm for human participants in audition and vision to explore the generality of the phenomenon. Participants’ task was to identify unexpected gaps in a structured stream in an identical manner in the visual and auditory modalities. The stream had 3-element intensity or duration patterns to probe segmentation biases.
We found that variability in sensitivity to gap deviations showed similar, pattern-derived biases across the two modalities. This sensitivity bias could be explained neither by the repetition of individual elements nor by the absolute feature value (e.g. duration, intensity) of the individual elements alone. Instead, this bias depended on the internal repeating structure of the stream and it had an effect even when conscious recognition of the structure itself did not occur.
We also analyzed neuronal activity in the auditory cortex (AC) of awake, head-fixed mice passively exposed to similar acoustic stimuli to see how AC neurons respond to changes within a continuous stream. We found that AC activity significantly increased in response to stimuli featuring unexpected gaps, again, as a function of their position in the pattern.
By employing consistent paradigms across sensory modalities (auditory/visual) and experimental models (human/mouse), our results support the idea of domain-general non-linguistic grouping principles and raise well-testable further questions that have the capacity to lead to a domain-independent model of sensory processing.
Apart from its traditional definition as an autobiographical and temporally dated experience that can be consciously recollected, episodic memory can also refer to a trace of a momentary sensory input—a snippet of information that may serve either as a building block for developing more abstract representations or as a subconsciously accessed piece of memory. In both roles—as subconscious snippets and as components of abstracted knowledge—this kind of information requires consolidation for long-term retention. However, behavioral measures that clearly distinguish the consolidation of such snippets from that of abstractions, as well as the consequences of each type of consolidation, remain rare in the literature. We present a study aimed at achieving such a separation, based on the phenomenon of transfer learning, which involves the re-application of previously learned higher-level regularities to novel input. Previous empirical studies have investigated human transfer learning in supervised or reinforcement learning settings, typically focusing on explicit knowledge. Consequently, it remains unknown whether such transfer occurs naturally during the more common type of implicit and unsupervised learning—and, if so, how it relates to the consolidation of nonspecific, unconscious memory across different levels of abstraction. We compared the transfer of newly acquired abstract knowledge—ranging from somewhat explicit to fully implicit—during unsupervised learning by extending a visual statistical learning paradigm to a transfer learning context. The visual statistical learning paradigm exposes observers—without any task—to a large set of compound images composed of separate shapes and subsequently measures sensitivity to hidden structures, such as pairs of shapes that consistently repeat within the stream. We introduced higher-level features into the paradigm by biasing the dominant orientation of the hidden pairs to be either horizontal or vertical. In the transfer phase, all shapes were replaced with a new, never-before-seen set, and we measured how the horizontal or vertical structure embedded in the first phase influenced the implicit learning of new pairs of any orientation in the second phase. Using this method, we found evidence of transfer during unsupervised learning, but with important differences depending on the explicitness or implicitness of the acquired knowledge. Observers who acquired more explicit knowledge of pair associations (without awareness of the dominant orientation structure) during the initial learning phase were able to immediately transfer the general orientation information to the second phase by learning similarly oriented pairs better. In contrast, observers with the same amount of implicit knowledge showed the opposite effect—structural interference during transfer. Importantly, when sleep occurred between the learning phases, these implicit observers—while still remaining unaware of structures—shifted their behavior and exhibited the same pattern of transfer as the explicit group. This effect was specific to sleep and did not occur after a comparable period of wakeful consolidation. Our results highlight both the similarities and differences between explicit and implicit learning, as well as the influence of available explicit and implicit knowledge on the acquisition of generalizable higher-level knowledge. They also underscore the complex role of consolidation in restructuring internal representations.
Statistical learning—extracting the underlying structure of complex environments from ongoing exposure to sensory inputs—is a key mechanism by which humans and other animals acquire generalizable internal representations of the world (i.e., a form of semantic memory). While the kinds of statistical structures that are extracted from stimuli over the course of statistical learning, and the way they generalize to novel test stimuli, have been characterized in great detail, the resulting internal representations have typically been assessed by two-alternative forced-choice tests that simply measure generic familiarity (i.e., memory strength). Hence, it remains unknown how the learning of statistical structure is related to learning, storing, and recalling memories with fine detail and context. Conversely, recognition-memory research has characterized the specificity and context-dependence of memories by using test methods that analyze hit and false-alarm rates of memory judgements through Receiver Operating Characteristic (ROC) curves. Based on these studies, the dual-process theory posits that recognition memory relies on two distinct processes: familiarity and recollection (retrieval of contextual details). However, recognition memory has typically been studied using stimuli that had strong pre-existing semantic representations (e.g., words, natural scenes), and in particular test stimuli that were either exactly repeated from training or entirely novel. Thus, it remains unknown how memories of non-semantic stimuli are recalled and in particular how familiarity and recollection contribute to memory-based generalization. As a first step toward unifying these fields, we investigated whether the dual-process theory generalizes to memory representations emerging through visual statistical learning. Across six online experiments (each with N = 50), participants completed recognition tasks after exposure-based learning requiring different degrees of generalization between familiarization and test. In Experiment 1, participants were familiarized with pairs of simple visual shapes and tested on either the same pairs (targets) or recombined pairs (lures). In Experiment 2, we replaced the shapes in the lures with entirely novel shapes. In Experiment 3, we tested individual familiar shapes against novel shapes, while in Experiment 4, we reversed the structure of Experiment 3 by familiarizing participants with single shapes and testing them on pairs. Experiment 5 involved single-shape familiarization and testing, and Experiment 6 repeated Experiment 1 but with increased. Across these experiments, we found that recollection probability was highest when participants were tested on single items. Conversely, familiarity was stronger when fewer items were presented during familiarization and when novelty contrast was higher at test (e.g., Experiments 2 vs. 1). Prior recognition-memory studies suggest that item recognition should engage both recollection and familiarity, while associative recognition (distinguishing true vs. recombined pairs) should rely primarily on recollection. Our results support the joint contribution of recollection and familiarity in experiments with tests based on items. However, in contrast with previous findings, we find that recognition in non-semantic contexts is predominantly driven by familiarity. In addition to this indication of differences in how semantic and non-semantic stimuli engage familiarity and recollection, the present study highlights the paramount influence of contextual factors, such as familiarization–test relations, on recognition performance.
 Proposals differ on how the brain accounts for the uncertainty of perceptual variables–either by representing them as probability distributions that explicitly encode uncertainty in their width (Knill & Pouget, 2004), or by exploiting the correlation between the uncertainty of one variable (e.g., orientation) and the value of others (e.g., contrast), using the latter’s point estimates as heuristic proxies (Bertana, Chetverikov, van Bergen, Ling, & Jehee, 2021). The two approaches offer distinct advantages — probabilistic representations provide superior data- and memory-efficiency, while proxy-based strategies impose substantially lower computational demands–and each has its proponents, depending on which advantage is considered more relevant to brain function (Barthelmé & Mamassian, 2010; Meyniel, Sigman, & Mainen, 2015; Koblinger, Fiser, & Lengyel, 2021). Rather than strictly contrasting these hypotheses, we follow a normative perspective and argue that both strategies can emerge naturally in a unified framework when time-evolving approximate inference is optimized to solve realistic tasks involving the joint estimation of multiple interacting variables. We formalize this idea by modeling behavior as the output of an ideal observer that combines approximate probabilistic perceptual representations with fast, coarse proxy information–yielding a flexible hybrid approach. Through simulations, we show that the model adaptively relies on proxies to compensate for the coarseness of approximate inference. Finally, by directly comparing the model’s output to empirical data, we demonstrate that observed behavior qualitatively aligns with the predictions of this hybrid model.
Proposals differ on how the brain accounts for the uncertainty of perceptual variables–either by representing them as probability distributions that explicitly encode uncertainty in their width (Knill & Pouget, 2004), or by exploiting the correlation between the uncertainty of one variable (e.g., orientation) and the value of others (e.g., contrast), using the latter’s point estimates as heuristic proxies (Bertana, Chetverikov, van Bergen, Ling, & Jehee, 2021). The two approaches offer distinct advantages — probabilistic representations provide superior data- and memory-efficiency, while proxy-based strategies impose substantially lower computational demands–and each has its proponents, depending on which advantage is considered more relevant to brain function (Barthelmé & Mamassian, 2010; Meyniel, Sigman, & Mainen, 2015; Koblinger, Fiser, & Lengyel, 2021). Rather than strictly contrasting these hypotheses, we follow a normative perspective and argue that both strategies can emerge naturally in a unified framework when time-evolving approximate inference is optimized to solve realistic tasks involving the joint estimation of multiple interacting variables. We formalize this idea by modeling behavior as the output of an ideal observer that combines approximate probabilistic perceptual representations with fast, coarse proxy information–yielding a flexible hybrid approach. Through simulations, we show that the model adaptively relies on proxies to compensate for the coarseness of approximate inference. Finally, by directly comparing the model’s output to empirical data, we demonstrate that observed behavior qualitatively aligns with the predictions of this hybrid model.
Hierarchical Bayesian models offer a unified framework for understanding both learning and meta-learning — the transfer of abstract knowledge across tasks. We investigate whether these two processes are dissociable through a novel statistical learning paradigm that combines low-level shape pair structures with a higher-order color-based rule. 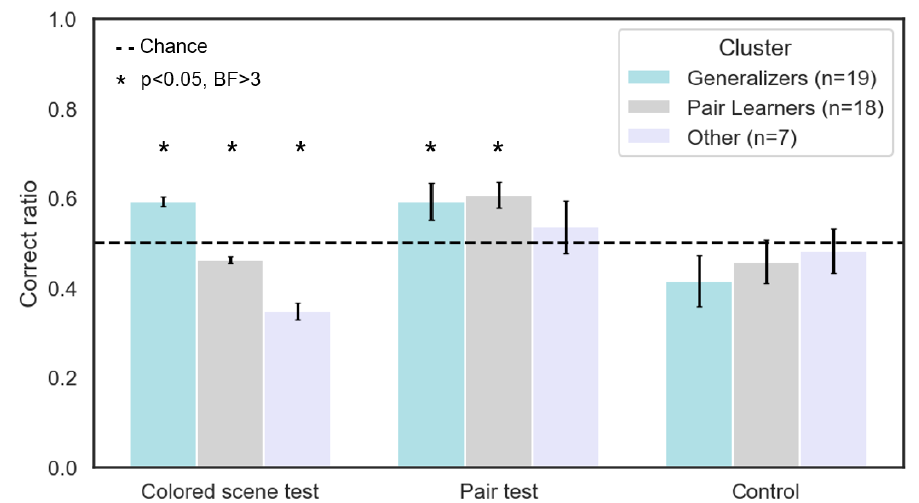 Participants viewed shape scenes organized into covert pairs with consistent color contrast patterns (the pepita rule), followed by tests assessing recognition of both pair-level and meta-structural regularities. Subject-level analyses revealed three learner profiles: (1) those who acquired both low- and high-level structures, (2) those who learned only low-level pairs, and (3) non-learners. Notably, strong low-level learning was a prerequisite for successful meta-learning, aligning with predictions of hierarchical models. These findings support a behavioral dissociation between learning and meta-learning and highlight individual differences in abstract knowledge acquisition and transfer.
Participants viewed shape scenes organized into covert pairs with consistent color contrast patterns (the pepita rule), followed by tests assessing recognition of both pair-level and meta-structural regularities. Subject-level analyses revealed three learner profiles: (1) those who acquired both low- and high-level structures, (2) those who learned only low-level pairs, and (3) non-learners. Notably, strong low-level learning was a prerequisite for successful meta-learning, aligning with predictions of hierarchical models. These findings support a behavioral dissociation between learning and meta-learning and highlight individual differences in abstract knowledge acquisition and transfer.
Biases in perceptual decision-making tasks serve as indicators of both short-term serial effects and long-term inferential strategies. While recent studies have provided mixed results on how adding a secondary confidence measurement task affects decision accuracy, there is little information on how such confidence measurements influence the reasoning behavior that underlies perceptual biases. Recently, we reported a new long-term bias in a sequential decision-making paradigm that reflected the contextual model participants used to interpret events during the experiment, leading to radically different, sometimes counterintuitive, behavior. In the current study, we investigate the effect of pairing different confidence measurements with this decision-making task on the reported long-term biases. We used a 2AFC decision-making task with four conditions, based on two factors: the timing of confidence measurement—either introduced only during the test phase or present throughout both training and test phases—and the method of confidence measurement: instantaneous joint reports of decision and confidence versus 2-step reports. To maximize contrast, we chose two very distinct implementations of confidence-reporting paradigms. In the first, confidence was inferred from movement dynamics in a mouse-tracking task, where participants indicated their decision by drawing a leftward or rightward stroke, with stroke length encoding confidence. In the second, participants provided explicit confidence ratings via a post-decision continuous slider. We found that introducing confidence assessments did not significantly alter the reasoning behavior observed in sequential decision-making, as overall long-term biases remained the same. This suggests that these biases stem from stable internal models. The method of confidence measurement may or may not alter these results, indicating an independent effect of measurement method on the reasoning strategy. In summary, the selection of internal decision-making models determining observable decisions and biases remains intact with the addition of the confidence-reporting task, but these models are not independent of the method used to measure confidence.
A staple feature of object representation and perception is invariance: stable representation of new objects is learned from perpetually varying visual inputs and objects are identified as same despite of large differences in the appearance of their local features. Yet, visual statistical learning (VSL) paradigms investigating the formation of such object representations typically use static images of standardized visual patterns as local features. In three experiments using a Virtual Reality environment, we explored how human VSL is affected when the stable visual structures to be learned appear in a more natural dynamic manner by where the classical spatial VSL patterns appeared in a plane that perpetually changed its 3D position, rolled, pitched and yawed in a random fashion. First, we replicated the classical static results showing that adults have a significant familiarity preference (59%) for shape-pair structures that were used to generate composite scenes in the preceding task-free exposure phase of the experiment. Next, we rerun the experiment with moderate dynamic movement of the plane during the exposure phase and found that preference became indistinguishable from chance performance indicating the disappearance of implicit learning under these conditions. In the third experiment, we increased further the magnitude of the dynamic movement of the plane holding the composite patterns. Surprisingly, instead of staying in the ”no-learning” regime, participants developed a significant familiarity preference for the alternative lure shape pairs during the test trials (40%). This preference was significantly different not only from chance performance but also from the preference in the moderate condition. These results suggest that instead of being simply eliminated, the effects of dynamic variations in the input during exposure are associated with the features and can take part in active interference during the familiarity judgement.
Understanding the relationship between statistical learning and recognition memory is essential for explaining how environmental input is encoded and recalled. While statistical learning has been extensively studied in visual paradigms, recognition memory research has typically involved semantically rich stimuli such as words and images of natural scenes. The present study bridges these fields by examining how previous findings in recognition memory generalise to paradigms where simple, non-semantic visual stimuli is used. In seven experiments, participants completed recognition tasks with shape stimuli. In the item recognition task (n = 150), participants distinguished between previously viewed shapes and novel lures. In the association recognition task (n = 200), participants judged whether pairs of shapes were previously viewed or recombined from familiar shapes. Unlike traditional paradigms, our study used a small stimulus set and a single familiarization-test block. The stimulus presentation times during familiarization and inventory sizes were varied between participants. Prior research suggests item recognition depends on both familiarity and recollection, while association judgments rely mainly on recollection. Our findings confirm this for item recognition but reveal that associative memory judgments are primarily driven by familiarity, contrary to prior studies. This challenges earlier models, indicating that recognition processes are influenced not only by task type but also by stimulus characteristics and experimental design. Moreover, reducing the study list length in the association task further amplified familiarity’s role, contradicting previous claims linking list length solely to recollection. These results underscore the impact of contextual factors on recognition memory and suggest a more prominent role for familiarity in tasks involving non-semantic stimuli.
2024
Recently, we provided evidence that similarly to simple visual stimuli, such as Gabor patches, rich episodic stimuli are also encoded in and recalled from long-term memory with their subjective uncertainty, indicating a probabilistic representation of memory details. However, it is unknown how this probabilistic form of representation and episodic recall accuracy are affected at various input/set sizes in situations with added underlying regularities (compact distribution of possible orientations) and when subjects’ attention levels vary. To address these questions, we conducted multiple memory experiments (N = 180), in which participants first viewed a varying number of individually presented oriented objects and later had to recall the objects and their orientation together with their subjective uncertainty. Probabilistic encoding was indicated by calibratedness—the degree of correlation between memory accuracy and subjective uncertainty. We found that at smaller set sizes, added orientation regularity significantly improved episodic recall, while increased attention modulated the critical set size where this effect appeared. At larger set sizes, calibratedness became biased at lower levels of certainty, but completely disappeared only when subjects failed to recall the stimulus. High attention also modulated the critical set size determining the onset of bias in calibratedness, as with accuracy. Importantly, objects recalled with the highest accuracy remained unaffected by underlying input structure, both regarding the reported orientation and calibratedness. Our results demonstrate that people extract underlying input regularities successfully both with low and high attention in object viewing, although in each case, they seem to prioritize item-based encoding and utilize the underlying structure as a guide. Further, calibratedness remains high whenever object memory is vivid and disappears only when subjects cannot remember anything from the individual objects, suggesting that probabilistic encoding is the default form of representing the details of long-term episodic memories, regardless of attention, set size, and input characteristics.
Traditionally, statistical learning (SL) studies in the auditory domain have been linked to language processing and, therefore, to sequential predictability or “temporal” structure learning. In contrast, research on visual SL has focused more on discovering general spatio-temporal patterns, which requires spatial structure learning. We asked whether this dichotomy is justified or if auditory SL should also be considered within the more general framework of domain-independent discovery of spatio-temporal patterns. In three auditory experiments, we used the co-occurrence statistics of the classical visual spatial SL paradigm without and with spatial information included. From co-occurring but spatially not separated auditory patterns of “scenes” with up to four different sounds presented concurrently, human adults learned the same statistics as in visual SL tasks of underlying pair-based chunks. When, with the help of a two-dimensional loudspeaker grid, the auditory stimuli were presented in a spatial layout that tightly followed the structure of earlier visual studies, the number of sounds in the scene adults could parse into chunks went up by 50%. In addition, depending on the difficulty of the task, adults learned the different statistics to different degrees. These results support the idea of treating auditory and visual statistical learning in a joint framework.
Statistical learning is a fundamental mechanism underlying the acquisition of the regularities of the sensory environment, however, understanding of the learning process itself is still rudimentary. We assessed pupil diameter and eye movements as potential continuous indicators of spatial statistical learning in free visual exploration using a gaze-contingent stimulus presentation. In 3 studies (N=154) using an active spatial statistical learning paradigm and manipulating the length and the explicitness of learning, we found that after sufficient learning (~15 mins of exposure), pupil size was larger on interleaved trials that violated the previously encountered regularities than on trials that fit earlier patterns. Additionally, there was an increase in eye movements in directions consistent with the underlying statistical structure. Importantly, the strength of these effects was correlated with performance on the subsequent familiarity test, both with explicit and implicit learning instructions. Finally, the two measures exhibited contrasting outcomes in terms of awareness of the statistical structure with implicit learning instructions: eye movements emerged as a more effective indicator of awareness of the learned structures, whereas pupil size proved to be a robust predictor of individual learning performance among implicit learners lacking awareness.
Recent studies, employing for example a roving paradigm, established that perceptual learning (PL) is substantially influenced by the statistical structure of the task conditions. However, existing computational models, based primarily on feedforward architectures, struggle to adequately account for these learning effects that depend on higher-level statistical contingencies embedded in the structure of the task. We propose a Bayesian framework that uses contextual inference to represent multiple learning contexts simultaneously with their corresponding stimuli. The model infers the extent to which each reference-context might have contributed to a given trial and gradually learns the transitions between reference-contexts from experience. In turn, the correct inference of the current reference-context supports efficient neural resource allocation for encoding the stimuli expected to occur in the given context. This reallocation of resources maximizes discrimination performance and strongly modulates PL. Our model not only reconciles parsimoniously previously unexplained roving effects observed in PL studies but also provides new predictions for learning and generalization. These results demonstrate that statistical learning and its higher-level generalization, structure learning, form a functional symbiosis with lower-level perceptual learning processes.
Our sensory system automatically and unconsciously extracts patterns at varying complexity from the environment, and these patterns bias sensitivity to changes, accuracy during recognition, and also guide attention. A growing body of evidence shows that sensory integration starts at low-level cortical areas, as neural correlates of temporal integration (chunking) are already present in the primary sensory cortices. Based on this, we hypothesized that certain chunking principles and the resulting perceptual biases are similar across modalities. To test our hypothesis, we focused on a well-known auditory chunking principle called the Iambic-Trochaic Law (ITL). Established in language processing, ITL says that longer syllables in a sequence signal word ends, and similarly, longer duration of a tone is understood as a closing element of a perceptual chunk. ITL is considered a basic law since it has been found across multiple species, but it is unknown whether it generalizes across modalities. We implemented a Short-Short-Long stream segregation go/no-go paradigm for human participants in identical manner in the visual and auditory modalities and found that although the general performance was lower in vision, biases in sensitivity to deviations showed the same bias in the two domains (N=17). Extending the paradigm to a Short-Long-Long stream, we replicated the basic effect while clarifying that this sensitivity bias could neither be explained by the repetition of individual elements nor by the absolute duration of the individual elements alone in either sensory domain. Instead, this bias depended on an unconscious chunking process that integrated effects related to both duration of the individual elements and internal structure of the stream, such as the number and arrangements of the long elements. Our results support the existence of domain-general non-linguistic grouping principles incorporating structural features of ever increasing complexity that could ultimately give rise to high-level chunks leading to object concepts.
Cognitive fallacies are examples of breakdowns in human reasoning in which observers make irrational decisions as evaluated by Bayesian probability calculus. These examples were used for arguing that human reasoning does not operate by the rules of probabilistic computation, in contrast with the surging trend of studies demonstrating that at the level of perceptual decisions, human behavior can be described well by probabilistic models. While multiple studies pointed out flaws in the investigations of cognitive fallacies, a comprehensive and quantitative treatment of the topic is missing. We provide such a treatment by placing perceptual decision making into a new framework and linking it to the problem of the “Base-rate fallacy” (BRF), one of the most celebrated cognitive fallacies. In BRF, individuals participating in vignette studies apparently do not consider the base-rate probabilities of events (priors) when making judgmental decisions. We created a standard 2-AFC perceptual decision making paradigm (N=23) where observers decided which of two shapes embedded in noise was presented in the trial, added one moment in the trial sequence (change point, CP) where significant change occurred to the conditions of the trials and measured behavior in trials well after the CP. We uncovered that humans’ decision making under such conditions shows a far more complex but still probabilistic behavior than reported before. Generalizing this process, we found that keeping the process identical except for changing higher-level noise characteristics of the setup at the CP, humans flip between interpretations of the input relying vs. not relying on assumed differences in the base rates, perfectly mimicking the BRF. In conclusion, instead of being evidence for the lack of probabilistic treatment of the input, cognitive fallacies might be indicators of the same internal model based on probabilistic computations seamlessly transitioning into a particular unconscious interpretation of the current situation.
In the standard signal detection (SDT) framework, assuming that observers’ decisions (Type 1 decision) and confidence (Type 2 decision) about decisions are based on the same information, their sensitivity (d’) to sensory stimulus can be assessed both from decision accuracy and confidence reports. However, ample empirical evidence indicates that d’ derived from these two sources are not equal, suggesting that Type 1 and 2 decisions rely on at least partially distinct information. Based on this insight, several studies explored the use of d’ derived from Type 2 decisions independently (meta-d’) to characterize metacognitive performance. The resulting single core algorithm used by most popular methods is built to follow the logic of standard SDT without explicitly defining a normative framework. By developing a normative generative model of metacognition and through theoretical analyses and simulations, we found that the core algorithm does not fit the natural extension of the classical SDT-based generative model. It provides correct measures—according to the natural extension—only in the case when no added or subtracted noise is assumed during the confidence judgment compared to the decision stage, i.e. when d’ = meta-d’. For example, at a typical value of d’ = 1.16, if meta-d’ deviates from d’ by 10%, the core algorithm will predict as much as 30% deviation. As a result, using the core algorithm eliminates the rigorous link between the descriptions of Type 1 and Type 2 decisions, and in turn, the fundamental logic of the M-ratio-based metric using meta-d’/d’ is called into question. In contrast, our analysis also provides a computational method of meta-d’ that restores the link while adhering to the normative generative framework. In conclusion, we identified a significant flaw in the popular method of treating Type 2 decisions and provided a normatively justified algorithm for assessing metacognitive performance.
 To be efficient, both active learners and teachers need to be able to judge the relative usefulness of a piece of information for themselves or for their students, respectively. The current study assessed whether experience of active learning facilitates subsequent teaching from imperfect knowledge. Following a visual category learning task, dyads (N=40) of active and yoked passive learners taught (imagined) naive learners how to categorize the same visual stimuli by providing them with a small number of self-generated examples. Active learners narrowed down the possible categorization boundaries more than yoked learners. However, the active learning advantage was modest and limited to categories that were more difficult to learn and, overall, teachers were overly conservative, providing the least ambiguous category examples.
To be efficient, both active learners and teachers need to be able to judge the relative usefulness of a piece of information for themselves or for their students, respectively. The current study assessed whether experience of active learning facilitates subsequent teaching from imperfect knowledge. Following a visual category learning task, dyads (N=40) of active and yoked passive learners taught (imagined) naive learners how to categorize the same visual stimuli by providing them with a small number of self-generated examples. Active learners narrowed down the possible categorization boundaries more than yoked learners. However, the active learning advantage was modest and limited to categories that were more difficult to learn and, overall, teachers were overly conservative, providing the least ambiguous category examples.
2023
Maintaining an accurate internal model of our changing environment is essential for efficient decision-making. Previous studies of perceptual decision making were focusing almost exclusively on overly simplistic situations, in which observed changes could be accounted for by a single parameter of the internal model. We extended these investigations to more realistic situations when changes in external conditions could be explained by multiple, equally feasible variants of the complex internal model through the adjustment of its multiple parameters simultaneously. Using Bayesian ideal observer analysis and a novel behavioral 2AFC visual discrimination paradigm, we developed a method in which we could use observers’ response biases to identify the internal representations they used during decision making. We found by computational modelling and verified by a set of experiments that in such complex tasks, observers’ interpretation was strongly modulated by the specific dynamics of the sequential input. We showed that this behavior could be qualitatively captured by assuming that observers rely on hierarchical representations with detailed dynamics of each parameter of their internal model and use this information for readjusting their model to properly account for the changes in the input sequence. To verify that our Bayesian model fits were correct, we used a strong form of cross-validation: First, we demonstrated that the parameters of the abstract Bayesian model naturally map to the parameters of a process-level sequential sampling model, then we showed that this process-level model could in turn explain idiosyncratic reaction-time patterns present in the behavioral data that were out of the scope of the original Bayesian model. Importantly, our results are compatible with a fully Bayesian view of perceptual decision making, in which uncertainty at various levels of the complex internal model representing and interpreting the external input is optimally accounted for. Our approach provides a new way of investigating human complex decision making.
To generate efficient behavior, probabilistic theories of perception propose to link internal representations and the incoming sensory input based on the subjective uncertainty the observer has about them. Episodic memories, that is episodes experienced earlier by the observer, are a significant part of the internal representations, yet it is unknown whether they are encoded with their uncertainty and if so, what governs the uncertainty of an episode. To address this issue, we conducted memory experiments on the encoding of episodic events, in which participants (N = 95) viewed a set of individually or concurrently presented oriented objects and later they had to recall these objects and their orientation and provide their subjective certainty about the orientation. The orientation of the objects in separate experiments was sampled from a uniform or Gaussian (bumped) distribution or in a condition when two of the three objects in each scene had identical orientation (glued). Calibratedness, the correlation between accuracy of the orientation and subjective (un)certainty was used to detect probabilistic coding. Recall of individually or concurrently presented objects with uniform orientation distribution confirmed that observers’ coding of these episodes was highly calibrated. The “glued” results showed significantly different overall accuracy between glued and unglued objects with nonsignificant correlation within a scene. Since correlations in accuracy between the two glued objects within a scene were significant, the overall advantage of glued objects had to originate from attention being drawn to the glued structure rather than better memory of certain scenes. Bumped results showed higher overall accuracy but reduced calibratedness indicating an effect of the learned meta-structure: both certain and uncertain guesses utilized the bump information. These results support the idea that, similarly to incoming sensory information, episodic memory is treated probabilistically in perceptual processes and that this process relies on both within-scene and across-scene structures.
The brain encodes dynamic sensory information along different modalities effectively and accurately into structured representations by relying on various biases of different complexities. While the ultimate representation is multimodal, the biases used for encoding have been defined at the level of individual modalities despite a growing body of evidence showing that integration is already present at low-level cortical areas. We hypothesized that for efficient multimodal encoding the applied biases should also be similar across different modalities. We focused on two modalities -auditory and visual- and measured whether a well-established bias in auditory research, the Iambic-trochaic Law (ITL) also appears in the visual modality when the core dimensions of processing dynamic information are properly controlled. According to ITL, when a temporal structure of an auditory stimuli train consists of short (S) and long (L) objects separated by silence (…SSLSSLSSL…), the auditory system tends to rapidly interpret the stream as a repeating pattern of SSL rather than any other alternatives (e.g., SLS) as confirmed by decreased detection accuracy of randomly inserted short gaps at a perceived pattern’s border. To test the universality of ITL, first, we used a change detection go/no-go paradigm and a within-subject design (N=18) to assess the effect of simple feature changes on temporal resolution: we manipulated the duration (presentation time) of the alternating “object” (tone/square) and “background” (silence/gray background) and object intensity. Next, we used the same paradigm to test ITL in the two modalities (N=15). We found that although the general performance was lower in vision, biases in sensitivity towards objects and shorter repetitions were shared principles across modalities, and ITL temporal chunking bias could be identified in the visual results. These results provide an important initial step toward building a unified computational model for modality-independent sensory perception.
While studies on visual statistical learning focus on how specific chunks based on co-occurrence of observable elements are learned, they typically neglect exploring the role of knowledge about the higher-level structure of these chunks in learning. We studied this role of structural knowledge by investigating how first being exposed to only horizontal or vertical shape-pairs in scenes affected the subsequent implicit learning of both vertical and horizontal pairs defined by completely novel shapes. In 6 experiments, we found that participants with more explicit knowledge of individual pairs were immediately able to generalize structural knowledge by extracting new pairs with matching orientation better and they kept this ability after both awake and sleep consolidation. In contrast, participants with weaker, more implicit knowledge and without consolidation showed a structural novelty effect, learning better new non-matching pairs. However, after sleep consolidation, this pattern reversed and they showed generalization similar to the “explicit” participants. This reversal did not occur after awake consolidation of the same duration as participants showed strong proactive interference and learned no new pairs. We validated our findings by multiple measures of explicitness both at the participant level (free report) and at the item level (confidence judgments) and by inducing explicitness via instructions. Furthermore, matched sample analysis revealed that the difference between “explicit” and “implicit” participants was not predicted by different strengths of learning in the first exposure phase, but only by the quality of the structural knowledge. Our results show that knowledge of higher structure underlying visual chunks is automatically extracted even in an unsupervised setup and has differential effects depending on the complexity of the extracted knowledge. Moreover, sleep consolidation facilitates transformation of structural knowledge in memory. Overall, these results highlight how momentary learning interacts with already acquired structural knowledge, leading to complex hierarchical knowledge of the visual environment.
Accumulating behavioral and neural evidence suggests that incoming sensory input is represented and combined with generalized semantic knowledge in a fundamentally probabilistic way during perceptual processes. Recently we provided evidence that human perceptual decision making is fully probabilistic (encodes uncertainty of all internal variables) rather than task-dependently probabilistic (encoding uncertainty only at the level of decision variables). However, episodic memories are traditionally treated outside of this perceptual context. Hence, it is unknown if episodic memories are also treated probabilistically, that is, whether they are encoded and recalled with their uncertainty just as immediate sensory information is. To address this question, we conducted an episodic memory study, in which participants (N=76) first viewed a set of objects presented either individually or in scenes and later they had to recall the orientation of those objects and indicate their uncertainty about their responses. We used the well-calibratedness of orientation responses, i.e., the level of positive correlation between participants’ subjective certainty and orientation accuracy as the indicator of the probabilistic encoding of episodic memory. Our results showed a recall performance with object orientation substantially lower than performances reported in earlier studies with semantic features. This indicates that memory is not equally massive for all object dimensions. More importantly, at any time when orientation recall accuracy was significantly above chance, the participant’s responses became well-calibrated with highly significant positive correlations between participants’ subjective certainty and orientation accuracy for both individually presented objects (p < .004, BF = 10.2) and for objects presented in scenes (p < .001, BF > 100). These results suggest that encoding and recall of long-term episodic memory follow the same probabilistic principles as perception. This allows the momentary perceptual input, semantic knowledge and individual episodic memory traces to be treated and combined in a fundamentally uniform manner in the brain.
2022
While studies on spatial visual statistical learning typically focus on specific co-occurrence-based element chunks, they neglect the role of learning of the structure underlying these chunks. We study this structural learning by investigating the effect of first learning only horizontal or vertical shape-pairs on the subsequent learning of both vertical and horizontal (i.e. matching and non-matching) pairs defined by novel tokens. In 4 experiments, we show that participants with more explicit knowledge of pairs are immediately able to generalise structural knowledge by extracting new pairs with matching orientation better and keep this ability after both awake and sleep consolidation. In contrast, participants with more implicit knowledge and without consolidation show a structural novelty effect, learning better new non-matching pairs. However, after sleep consolidation, this pattern reverses and they show generalisation similar to the explicit participants. This reversal does not occur after awake consolidation of the same duration as participants show strong proactive interference and learn no new pairs. Our results show that knowledge of higher structure underlying visual chunks is extracted in vision and has differential effects depending on the quality of the extracted knowledge. In addition, sleep consolidation facilitates memory transformation to structural knowledge.
We present a framework in which Perceptual Learning, Statistical Learning and Rule/Abstract learning are not different types of learning but only differently specialized versions of the fundamental learning process, and we argue that this learning process must be captured in its entirety to successfully integrate learning into complex visual processes. First, we demonstrate how recent behavioral and neural results in the literature reveal a convergence across perceptual, statistical, and rule/abstract learning supporting this framework. Next, we show why the generalized version of statistical learning can provide the appropriate setup for such a unified treatment of learning in vision and present a computational approach that best accommodates this kind of statistical learning. We follow up by discussing what plausible neural scheme could feasibly implement this framework and how this scheme can help alleviate the present disconnect between neural measures and their interpretation from the standpoint of learning. We conclude with a case study, “roving” in visual learning, and by listing directions in the field where statistical learning needs to take steps to approach the level of sophistication required for being the method of choice for advancing our understanding of vision and other cognitive processes in their completeness.
Based on “phantom-word” experiments in auditory word-segmentation tasks, two contradicting sets of results and accordingly, two contradicting proposals about human language learning were reported recently. According to the first one, transitional probabilities are weighted higher than word frequencies, but relying purely on statistical information is not sufficient for word learning, additional prosodic cues need to be used. Using the same paradigm but obtaining the opposite result, the other study claims that statistical information is sufficient to segment streams into words and this behavior can be faithfully captured by a chunk-learning model. To resolve this contradiction, we show that an empirically supported probabilistic chunk-learning schema places the original test in a new context: as observers are exposed to the stream, they develop an internal representation that initially favors a simpler description of the environment that phantom-words provide, but with more exposure it switches to preference of true words instead. Therefore, segmentation through statistical learning is possible. In order to decrease the possible biases introduced by one’s native language, we test this explanation with segmentation tasks of non-linguistic noise streams rather than using classical word segmentation tasks. Our preliminary results in this non-linguistic acoustic domain are in line with our proposition.
Studies of spatial visual statistical learning (SVSL) typically focus on the implicit acquisition of co-occurrence-based element chunks oversimplifying the complex process of structure-based visual learning. We investigated the rules of SVSL under complex visual stimulus and task structures. In Phase 1 of the experiment (N=227), observers were exposed to scenes composed of either only horizontally or vertically arranged pairs of shapes, while in Phase 2, they saw scenes based on both horizontal and vertical pairs but using a new set of shapes. 2AFC tests measured observers’ pair-learning for both phases and open questions assessed the explicitness of their knowledge. Participants with complete explicit knowledge were excluded (N=3), while the others were grouped into implicit (N=192) and semi-explicit (N=35) groups based on their reported knowledge about pairs in Phase 1 being none or rudimentary without mentioning orientation. Learning in Phase 2 showed a strong double dissociation between the types of pairs learned preferentially and implicitness of knowledge. Observers with semi-explicit knowledge exceeded learning pairs in Phase 2 with the same orientation as in Phase 1, whereas implicit observers were better at learning pairs with non-matching orientation. Further analyses showed that this pattern was independent of the overall strength of pair learning in Phase 1, but critically depended on the implicitness/explicitness of knowledge. These results suggest that the strength of learning a higher-level structure of the input (here general orientation of pairs) has a crucial role in utilizing the acquired structural knowledge. As expected, when it is sufficiently strongly articulated, it helps generalization, i.e. learning similar patterns in a new context. In contrast, when it is weakly and implicitly captured -regardless of the overall efficiency- it hinders generalization and promotes a structural novelty effect.
Humans use their subjective uncertainty in their internal representations to make optimal decisions. However, perceptual uncertainty can have two components which have not been systematically distinguished or separately measured. Reducible uncertainty stemming from the noisiness of the system that can be modulated by external and internal factors such as contrast level or attention and that can be eliminated by integrating the noisy samples about the stimulus over extended time. In contrast, irreducible uncertainty originates from the inherent ambiguity of perception, it cannot be eliminated even with longer integration, and it lies at the core of the argument that perception is a probabilistic process. Previous studies reported evidence for representing uncertainty in early visual areas but have not clarified whether an irreducible component of uncertainty crucial for probabilistic perception is included in these low-level representations. To address this question, we used an orientation estimation paradigm, in which observers reported the perceived orientation of one of several briefly presented line segments or Gabor-patches together with their subjective uncertainty about their response. We varied looking time across trials and defined the irreducible component of uncertainty by the asymptotic level of performance in the limit of infinitely long looking time. We found a diverse modulation of reducible versus irreducible uncertainty by various stimulus properties. Contrast primarily affected reducible uncertainty, whereas increasing set size introduced irreducible uncertainty in perceptual representations. However, low contrast could also introduce irreducible uncertainty for more complex stimuli (Gabor-patches). Crucially, observers’ subjective uncertainty reports reflected both reducible and irreducible uncertainty and accurately followed their sum, total uncertainty. Our results indicate that perceptual representations reflect both the inherent ambiguity of perception and the internal noise of the system. This suggests that even low-level perceptual representations are fundamentally probabilistic, and appropriately take into account both kinds of uncertainties to achieve optimal decisions.
Recent studies established that perceptual learning (PL) is influenced by strong top-down effects and shows flexible generalization depending on context. However, current computational models of PL utilize feedforward architectures and fail to capture parsimoniously these context-dependent and generalization effects in more complex PL tasks. We propose a Bayesian framework that combines sensory bottom-up and experience-based top-down processes in a normative way. Our model uses contextual inference to simultaneously represent multiple learning-contexts with their corresponding stimuli. It infers the extent to which each context might have contributed to a given trial, and gradually learns the transitions between contexts from experience. In turn, correctly inferring the current context supports efficient neural resource allocation for encoding the stimuli expected to occur in that context, thus maximizing discrimination performance and driving PL. In roving paradigms, where multiple reference stimuli are intermixed across trials, our model explains a broad range of previously described learning effects: (a) disrupted PL when the references are interleaved trial-by-trial, and (b) intact PL when the references are separated into blocks, or when (c) they are interleaved across the trials but follow a fixed temporal order. Our model also provides new predictions for learning and generalization in PL. First, the amount of PL should depend on the extent to which the structure is learnt, predicting more PL in roving paradigms that use more predictable temporal structures between reference stimuli. Second, rather than depending solely on the low-level perceptual similarities of stimuli, generalization in PL should also depend on the extent to which higher-order structural knowledge about contexts (e.g. their transition probabilities) generalizes across different tasks. These results demonstrate that higher-level structure learning is an integral part of any perceptual learning process and that a joint treatment of high- and low-level information about stimuli is required for capturing learning in vision.
Who we choose to learn from is influenced by the relative confidence of potential informants. More confident advisers are preferred based on an assumption that confidence is a good indicator of accuracy. However, oftentimes, accuracy and confidence are not calibrated, either due to strategic manipulations of confidence or unintentional failures of metacognition. When accuracy information is readily available, people are additionally vigilant to the calibration of informants, penalizing incorrect, yet confident advisers (Tenney et al., 2007). The current experiment tested whether participants can leverage inferences about two advisers’ calibration profiles to make optimal trial-by-trial decisions. We predicted that choice of advisers reflects relative differences in the advisers’ probability of being correct given their stated confidence (recalibrated confidence), as opposed to stated confidence differences. The prediction was not supported by data, but calibration had a modulating effect on choices, as more confident advisers were more influential only when they were also calibrated.
Good teachers and good active learners share the ability to generate samples (examples or queries, respectively) that are informative in light of current knowledge. In line with this, the current experiment found that active learners outperformed yoked passive learners in a subsequent category teaching task. The learning task was replicated from Markant and Gurekis (2014) and included a manipulation of category structure (Rule-based or Information-Integration). Participants (N = 40 dyads) first learned how to categorize stimuli defined along two continuous perceptual features, and their subjective classification boundaries were inferred from categorization tests. During teaching, participants generated a small, fixed number of examples to teach the categorization boundary to an imagined learner. Improvements in teaching due to active learning went beyond what could be explained by better categorization performance prior to teaching, and example selection was modulated by participants’ degree of uncertainty about the boundary to-be-taught.
2021
While research on visual statistical learning (VSL) is divided into two distinct lines investigating the learning of temporal and spatial regularities separately, such a distinction does not hold in real-world environments, where the two types of regularities are perpetually intertwined as spatial patterns unfold over time. We investigated the interplay between spatial and temporal regularities in a new VSL paradigm, in which spatially defined chunks were continuously moving in and out of the observer’s view. First, participants passively observed a stream of stimuli in a task-free setup. Scenes composed of novel shape-pairs (oriented horizontally, vertically, or diagonally) were presented through a 3×3 grid aperture without between-pair segmentation cues. Periodically, the whole scene within the aperture moved a grid to a direction so that some shapes moved out and others moved in the aperture, thus showing particular pairs only partially sometimes. Subsequently, participants completed a 2AFC familiarity-task judging between real and foil pairs. In Experiment 1 (n=20), participants showed the same level of correct responses in this new setup as in classical spatial VSL experiments (M=61.11%, SE=3.19, p=0.003, BF=16.31). In Experiment 2a (n=73) and 2b (n=75), we introduced different levels of spatial noise by biasing the ratio between specific movement directions. More horizontal movement led to significantly more partial presentations (i.e. more noise) of horizontal than vertical pairs, and vice versa. Despite strong differences in the spatial conditional probabilities within the different types of pairs due to these manipulations, learning of pairs was not selectively hindered, observers performed equally well with all pair types. Evidently, observers can rely on the high temporal coherence of the evolving scenes to recover and represent the spatial structure regardless of spatial noise, and their learning is not a direct consequence of exposure frequency.
Co-association of an auditory and a visual event due to frequent co-occurrence have been reported to increase the size of their temporal binding window, that is the range of asynchronicity between the onset of the two events at which observers perceive them occurring simultaneously. According to a probabilistic interpretation, co-occurrence strengthens the prior that the two events originate from a common cause resulting in a higher degree of perceptual integration across modalities despite contradicting sensory evidence. However, statistical learning creating associations is considered to be a domain-general mechanism and as such, it should facilitate similar integration within a single modality as well, where distinctiveness of the two modalities cannot help. Using a simultaneity judgement task, we tested this conjecture by examining the change of observers’ sensitivity to asynchrony after implicit learning of co-occurrences within the visual modality. In a learning phase (LP), observers saw arbitrary shape-pairs moving synchronously in a random direction. In the test phase, three types of pairs were presented: 1) visual pairs seen during the LP, 2) pairs from the LP in a new combination, 3) pairs with completely new shapes. The asynchrony between the movement onset of the elements was manipulated. Observers showing learning during LP (N= 24) reported a higher proportion of simultaneity judgments, as quantified by higher temporal binding windows for the learned pairs than for the newly combined or novel visual pairs (p< 0.05) indicating an increased probability of unisensory integration despite identical sensory evidence. Thus, prior experience of high co-occurrence alters the perceived relation of elements in time within a single modality the same way as it does across modalities. These results point to a general mechanism of sensory binding across the entire spectrum of sensory input space.
Although statistical learning has been established as an important constituent of human implicit sensory learning capacities, the actual process of statistical learning rather than its outcome is largely unexplored due to the lack of appropriate measures. One candidate measure is changes in pupil diameter, which is known to be influenced by past experiences (e.g., violation of expectation, belief updating, pupil old/new effect), but has not been investigated in the more complex context of implicit statistical learning. We explored whether pupil dynamics of observers (N = 88) can be used as a continuous measure of statistical learning in a paradigm, where we manipulated the explicit knowledge of participants about the to-be-learned regularities of multi-element visual scenes. We introduced trials that violated the scene structure into the continuous stream of structured scenes presented during the learning phase. After an initial period of learning, pupil dilation was larger for these violation trials than for regular learning trials (p < 0.01). Importantly, during both explicit and implicit learning, the magnitude of pupil dilation for violation trials positively correlated with the amount of knowledge participants demonstrated at the subsequent test phase (r (explicit) = 0.44, p < 0.05; r (implicit) = 0.48, p < 0.01). We also found that observers with explicit prior knowledge about the underlying structure of the scenes demonstrated the emergence of these effects earlier during the learning phase compared to implicit learners without such knowledge. Our results demonstrate that pupil dilation can be used to track the accumulation of visual information, even in complex learning scenarios, irrespective of the explicitness of task instructions. Combined with research on eye-movements, our findings can be used for developing novel, active teaching-based experimental paradigms, in which the learning state is continuously assessed, and subsequent stimuli are selected accordingly for improved learning performance.
We investigated the influence of structural properties of previously learned stimuli on Spatial Visual Statistical Learning. Participants (n=170) were first exposed to a stream of scenes containing only one type of regularity (horizontal or vertical pairs), followed by a stream containing both types of regularities. We found that participants performed above chance for the pairs of the first stream (M=54.7%, SE=1.2, p<0.001, BF=91.89) as well as for the novel type of pair of the second stream (M=55.6%, SE=1.9, p=0.005, BF=4.04), but not for the familiar type of pair of the second stream (M=51.5%, SE=2.0, p=0.465, BF=0.11). This observed novelty effect indicates an interference between the similarly structured pairs in the first and second stream of scenes, suggesting representational overlap of pairs of the same orientation.
In collaborative tasks, humans can make better joint decisions by aggregating individual information in proportion to their communicated confidence (Bahrami et al., 2010). However, if people blindly rely on their partner’s confidence expressions, they could easily reach suboptimal solutions when their collaborator’s confidence judgments are not calibrated to their performance, but for instance exhibit an overconfidence bias. Given that calibrated advisers are rated as more credible (Sah et al., 2013), we propose that prior experience with a collaborator will lead to a recalibration of their confidence judgements before incorporating their advice. In an online experiment, participants first viewed two other fictitious participants, one calibrated and one biased, perform a categorization task. Following this, participants completed a similar task by taking advice from just one of the two previously observed advisers on a given trial. We tested whether participants chose the adviser who had the trial-by-trial highest expressed or recalibrated confidence.
Research on visual statistical learning (VSL) is classically divided into two independent lines: temporal and spatial VSL. However, for observers in real-world environments, spatial patterns unfold over time leading to a fundamental intertwining of both types of regularities. Using a new spatio-temporal VSL setup, we investigated the nature of this interdependence by moving spatially defined structures in and out of participants’ view over time. First, participants passively observed a large grid-like plane cluttered with novel shapes through an aperture of 3×3-grid moving over the plane for several minutes. Unbeknownst to the participants, the shape arrangement was composed of fixed pairs of shapes oriented horizontally, vertically, or diagonally and placed on the grid without any between-pair segmentation cues. The aperture moved by one grid cell into one direction periodically, so that some shapes moved out of the visible field while others moved in. This led to partial presentations of pairs at times as they entered or left the aperture, creating noise on the perceived spatial structure. After the passive exposure, participants’ acquired sensitivity to real vs. foil pairs was measured in a 2AFC-familiarity task. In Experiment 1 (n=20), participants showed the same level of learning in this setup as in classical static spatial VSL experiments (M=61.11%, SE=3.19, p=0.003, BF=16.31), demonstrating that learning of spatial structures is possible in dynamic contexts. In Experiment 2a (n=70), we manipulated the spatial noise of different types of pairs by enforcing more horizontal than vertical movement directions and thereby, showing more partial presentations of horizontal pairs than vertical pairs. All experiments were performed with both horizontal and vertical movement bias across different groups of participants leading to symmetrical results. In the condition with more horizontal moves, the bias led to an uneven decrease of spatial conditional probabilities within pairs from 1.0 to 0.67 (diagonal), 0.75 (horizontal), and 0.92 (vertical). In the control Experiment 2b (n=76), we used the same stimulus displays as the ones in Experiment 2a, but presented them statically and in scrambled order, thereby removing the temporal coherence of the stream while keeping the same level of spatial noise. Participants in the temporally coherent version (2a) learned significantly better overall than participants in the temporally scrambled version (2b) (F(1,144)=5.969, p=0.016) and in both experiments, they learned the diagonal better than the horizontal pairs (F(2,288)=3.601, p=0.029). On the one hand, our results confirmed the hypothesis that observers can rely on temporal coherence of the evolving scenes to recover the spatial structure of noisy input. Surprisingly, we also found that the success of learning the pair structure was not linked directly to spatial noise, as the diagonal pairs with higher noise were learned better than the horizontal pairs lower noise. Overall, these results indicate that the common assumption in spatial VSL that learning is a direct consequence of spatial statistics alone is an oversimplification.
2020
Due to the highly sequential nature of auditory information and its close link to speech in humans, auditory statistical learning (SL) has been viewed predominantly as a special learning related to segmentation in language development. Meanwhile in other modalities, SL has been conceptualized as a general-purpose learning ability of information presented in parallel, which is crucial for developing internal representations used by everyday behavior. To resolve this discrepancy, we investigated whether being exposed to brief auditory stimuli presented concurrently without any sequential structure across trials would lead to the same sort of automatic statistical learning as reported earlier with complex spatial patterns in the visual modality. Eight unique sound-segments were created by modifying everyday sound patterns such as rolling marble balls, dropping objects, etc., which were paired into four sound pairs. Following the standard SL paradigm, familiarization auditory “scenes” were created by randomly pairing two of the pairs for each scene so that elements of a pair never appeared without each other during the familiarization, but they were paired with all other sounds equally often. Thirty-six participants (Exp1=14, Exp2=22) listened to the sequence of 360 scenes in random order, to all four segments of each scene together for 1.5 sec, without any instruction beyond asking to pay attention. Next, in the test session, participants chose which of two sound pairs (a true pair vs. a random combo) sounded more familiar. In Exp1, sensitivity to joint probability, in Exp2, sensitivity to conditional probabilities of sounds were tested. In both experiments, participants showed a significantly above-chance preference (p<0.001) for the pairs with a higher joint/conditional probability, fully replicating earlier results obtained in the visual domain. This suggests that rather than being specially language-related, auditory information is used by general-purpose SL for shaping internal representation the same way as in other modalities.
2019
Abstract: Repeated perceptual decision-making is typically investigated under the tacit assumption that each decision is an independent process or, at most, it is influenced by a few decisions made prior to it. We investigated human sequential 2-AFC decision-making under the condition, when more than one aspect of the context could vary during the experiment: both the level of noise added to the stimulus and the cumulative base rate of appearance (how often A vs. B appeared) followed various predefined patterns. In seven experiments, we established that long-term patterns in the context had very significant effects on human decisions. Despite being asked about only the identity of the present stimulus, participants’ decisions strongly reflected summary statistics of noise and base rates collected dozens to hundreds of trials before. In addition, these effects could not be described simply as cumulative statistics of earlier trials: for example, a significant step change in base rate (a change point) could induce the same effect as a prolonged shift, while a gradual change did not induce any effect. As standard decision making models cannot explain these results, we developed a hierarchical Bayesian model that simultaneously represented the priors over the base rates and a potentially non-uniform noise model over the different stimulus identities. Based on simulations with the model, we conducted additional experiments and found that when a change occurred in the context that could be captured equally well by adjusting one or another aspects of the model, humans chose adjusting the variable that was less reliable as defined by variability in the preceding extended set of trials. In general, regardless of the simplicity of a perceptual decision-making task, humans automatically develop a complex internal model, and in the light of a detected change, they adaptively alter the component of this model that is implicitly judged to be the least reliable one.
Stimulus-independent fluctuations in the responses of sensory neurons are traditionally considered as mere noise, and thus a source of perceptual ambiguity. In contrast, sampling-based models of perceptual inference suggest that the magnitude of this intrinsic variability acts as a signal: it conveys information about the uncertainty in low-level perceptual estimates. In both cases, to improve accuracy, downstream areas need to average sensory responses over time, as in classical models of evidence accumulation. However, due to the different roles that upstream sensory variability plays under the “noise” and “signal” hypotheses, the uncertainty about this average behaves in fundamentally different ways in them: it is respectively related to the standard error or the standard deviation of responses. In order to compare these hypotheses, we used a modified orientation estimation paradigm in which, on every trial, subjects simultaneously reported their best estimate of one of several briefly viewed, static line segments and their confidence about this estimate. We varied the difficulty of trials by changing the number of line segments, their contrast level, and the presentation time of the display. In general, we found that subjects’ confidence predicted their accuracy even when controlling for these experimentally manipulated stimulus parameters. This indicated that subjects had a well-calibrated trial-by-trial subjective measure of their uncertainty and did not only rely on extrinsic stimulus parameters to gauge the difficulty of a trial. Critically, while both models could account for changes in estimation performance with stimulus parameters, only the “signal” model predicted correctly the experimentally observed changes in confidence reports, and in the strength of correlation between confidence reports and actual accuracy. These results offer a new psychophysical window onto the role of sensory variability in perception and indicate that it conveys useful information about uncertainty.
The sequential activation of neurons, reflecting a previously experienced temporal sequence of stimuli, is be- lieved to be a hallmark of learning across cortical areas1, including the primary visual cortex2,3 (V1). While circuit mechanisms of sequence learning have been studied extensively4,5, the converse problem, that is equally important for robust performance, has so far received much less attention: how to avoid producing spurious sequential activity that does not reflect actual sequences in the input? Here, we developed a new measure of sequentiality for multivariate time series, and a theory that allowed us to predict the sequen- tiality of the output of a recurrent neural circuit. Our theory suggested that avoiding spurious sequential activity is non-trivial for neural circuits: e.g. even with a completely non-sequential input and perfectly sym- metric synaptic weights, the output of a neural circuit will still be sequential in general. We then show that the most celebrated principles of synaptic organization, those of Hebb and Dale, jointly act to effectively pre- vent spurious sequences. We tested the prediction that cortical circuits actively diminish sequential activity, in an experience-dependent way, in multielectrode recordings from awake ferret V1. We found that activity in response to natural stimuli, to which animals were continually adapted, was largely non-sequential. In contrast, when animals were shown entirely non-sequential artificial stimuli, to which they had not been adapted yet, neural activity was sequential at first, and then gradually became non-sequential within a few minutes of extended exposure. Furthermore, this difference between responses to natural and artificial stimuli was not present at eye opening but developed over several days. Our work identifies fundamental requirements for the reliable learning of temporal information, and reveals new functional roles for Dale’s principle and Hebbian experience-dependent plasticity in neural circuit self-organization.
The effects of long-term history on sequentially performed perceptual decision making are typically investigated either under the simplest stationary condition or in the context of changing volatility of the event statistics defined by the generative process. We investigated the rules of human decision making in the more natural situation when changes in the external conditions could be explained away by multiple equally feasible adjustment of the internal model. In each of four experiments, observers performed 500 trials of 2AFC visual discrimination between two arbitrary shapes that could appear with different frequency across trials and were corrupted by various amount of Gaussian noise in each trial. Trials were split to practice and test, where at the transition between the two, the appearance probability of the shapes (AP) changed either abruptly or gradually, their relative noise characteristics (NOISE) were altered, and feedback stopped. Using hierarchical Bayesian modeling, we showed that in this setup, the same perceptual experience can be explained by assuming a change in either AP or NOISE, but the two alternatives induce opposite long-term biases and consequently, different behavior under uncertain conditions. Interestingly, we found that observers strongly preferred one of the two alternatives. However, by manipulating the nature of the AP and the NOISE transition, and the volatility of AP during training, observers’ behavioral biases and hence their implicit choice of explaining the situation changed toward the other alternative as predicted by the model based on the newly introduced uncertainty. This suggests that similarly to arbitration between habitual and model-based explicit learning, humans adjust their implicit internal model during perceptual decision making based on the reliability of the various components, which reliability is assessed across detected change points during the sequence of events.
Although some animals such as honeybees (Apis mellifera) are excellent visual learners, little is known about their spontaneously emerging internal representations of the visual environment. We investigated whether learning mechanisms and resulting internal representations are similar across different species by using the same modified visual statistical learning paradigm in honeybees and humans. Observers performed an unrelated discrimination task while being exposed to complex visual stimuli consisting of simple shapes with varying underlying statistical structures. Familiarity tests was used for assessing the emergent internal representation in three conditions exploiting whether each of three different statistics (single shape frequencies, co-occurrence probabilities and conditional probability between neighboring shapes) were sufficient for solving the familiarity task. We found an increasingly complex representation of the visual environment as we moved from honeybees to human infant and to adults. Honeybees automatically learned the joint probabilities of the shapes after extended familiarization, but didn’t show sensitivity to the conditional probabilities and they didn’t learn concurrently the single-element frequencies. As we know from previous studies, infants implicitly learn joint- and conditional probabilities, but they aren’t sensitive to concurrent element frequencies either. Adult results in this study were in line with previous results showing that they spontaneously acquired all three statistics. We found that these results could be reproduced by a progression of models: while honeybee behavior could be captured by a learning method based on a simple counting strategy, humans learned differently. Replicating infant’s behavior required a probabilistic chunk learner algorithm. The same model could also replicate the adult behavior, but only if it was further extended by co-representation of higher order chunk and low-level element representations. In conclusion, we’ve found a progression of increasingly complex visual learning mechanisms that were necessary to account for the differences in the honeybee, human infant- and adult behavioral results.
2018
The ability of developing complex internal representations of the visual environment is crucial to the emergence of humans’ higher cognitive functions. Yet it is an open question whether there is any fundamental difference in how humans and other good visual learner species naturally encode aspects of novel visual scenes. We investigated how honeybees encode instinctively various statistical properties of different visual scenes presented in sequence. While after limited exposure, bees became sensitive to statistics of only elemental features (e.g. frequency of A) of the scenes, with more experience, they shifted to relying on co-occurrence frequencies of elements (frequency of AB) and lost their sensitivity to elemental frequencies. However the bees failed to show sensitivity to conditional probabilities (if A then B) contrarily to humans. Thus, humans’ intrinsic sensitivity to predictive information might be a fundamental prerequisite of developing higher cognitive abilities.
We investigated feature ensemble encoding at the lowest level of visual processing by focusing on contour encoding in natural images. In such images, the mean contour is not a single value, but it varies locally with spatial position, and variability of the contour can be quantified by the noisiness of the contour segments. We used a novel image decomposition/recomposition method, three different classes of images (circular patterns, object and fractal images), and two types of noise (orientation and position noise) to generate stimuli for a 2-AFC pedestal noise discrimination task. We found that humans readily encoded variability of contour ensembles, this encoding systematically varied with image classes, and it was distinctively different for orientation versus position noise despite participants not being able to reliably distinguish between the two types of noise. Moreover, JND obtained with mixed orientation and position noise followed the optimal maximum likelihood estimate, supporting a probabilitic coding of contours in humans.
Statistical learning (ability to extract and store new structures) and perceptual learning (improve visual discrimination abilities) traditionally thought to deal with separate tasks at different levels of visual processing. To test this conviction, we investigated whether perceptual learning can be enhanced by the presence of a task irrelevant statistical structure. We trained two groups (N=16) of observers for 5-days to perform an orientation discrimination task. For one group, the background color of the scene changed across trials according to a fixed sequence, for the other, it changed randomly throughout the training. Overall, the fix group achieved a larger reduction in discrimination thresholds than the random group. Furthermore, there was a marked difference in performance of the two groups with different context. This suggests that task irrelevant statistical structure during perceptual learning is automatically and implicitly built in the developing internal representation.
The temporal relationship between sensory events plays a crucial role in establishing causal link between them, for example inferring a common cause. In the current study, we manipulated the probability of co-occurrence of various visual stimuli pairs to see whether this manipulation would affect participants’ ability to separate the two elements of a pair in time, when presented asynchronously. We used a simultaneity judgment task, with a learning phase, in which participants (N=14) saw synchronously disappearing shape-pairs, and a test phase, in which three types of pairs (learned, newly combined, novel) were presented, while the asynchrony between the disappearance of the elements was manipulated. Contrary to earlier results with cross-modal stimuli, a lower proportion of simultaneity judgments, as quantified by shorted temporal binding windows was reported for the learned pairs than for the newly combined or novel visual pairs indicating an increased probability of unisensory binding.
We investigated visuo-auditory statistical learning by using four visual shape and four auditory sound pairs and creating strong and weak cross-modal quadruples through manipulating how reliably a visual and an auditory pair occurred together across a large number of audio-visual scenes. In Exp 1, only the weak and strong quads were used, while in Exp 2 additional individual shapes and sounds were mixed in to the same cross-modal structures. After passive exposure to such scenes, participants were tested in three familiarity tests: (T1) visual or auditory pairs against pairs of randomly combined elements unimodally, (T2) strong cross-modal quads against weak ones, and (T3) visual or auditory pairs from the strong and weak quads against each other, unimodally. Without noise (Exp 1), participants learned all structures, but performed at chance in T3. In Exp 2, while T1 auditory was at chance, in the auditory T3, participants preferred strong pairs, showing a strong cross-modal boost.
We explored the interaction between perceptual learning and statistical learning, two domains of sensory learning that are traditionally investigated separately. Using a standard perceptual learning protocol, we trained observers to improve their sensitivity to orientation of Gabor patches while differentially manipulating task irrelevant context of the training, such as the background color of the training scenes. Overall, we found that irrelevant context not only strongly influenced observed perceptual learning performance, but it also induced highly specific effects in the post-training test determined by the statistical structure of the context modulation. Our results suggest that the task irrelevant statistical structure present in perceptual tasks is automatically and implicitly built in the developing internal representation during learning. Thus perceptual and statistical learning processes are strongly related and create an integrated and complex internal representation even in the simplest perceptual learning tasks.
Perceptual learning is defined as the ability to improve one’s performance in basic discrimination tasks via extended practice. Is this process influenced by statistical regularities in the scene that have no relation to the discrimination task at hand? Using a 5-day standard perceptual training protocol, we trained two groups of observers to perform an orientation discrimination task with Gabor patches. For one group, the background color of the scene changed across trials according to a fixed sequence, while for the other group, the background color changed randomly throughout the training. Baseline and post training discrimination thresholds were assessed in three conditions: (1) with randomly changing background colors, (2) with backgrounds following the fixed color sequence, and (3) with gray background. Overall, the group trained with fixed color sequence learnt more (had a larger reduction in orientation threshold by the end of the fifth day) than the group trained with randomly changing colors. Furthermore, while there was no difference across the baseline thresholds in the three conditions before training, after training, observers in the fixed sequence group showed the lowest threshold with fixed color sequence of the background, while their thresholds with random, and gray backgrounds were equally worse (higher). In contrast, observers in the random sequence group showed the lowest threshold during post test with the randomly changing background, intermediate thresholds with gray background, and the worst thresholds with fixed color sequence. Our results suggest that task irrelevant statistical structure in perceptual tasks is automatically and implicitly built in the developing internal representation during learning, and it can differentially affect the learning process. Moreover, altering such irrelevant context after learning has a highly specific effect on performance arguing for the emergence of a complex internal representation even in the simplest perceptual learning tasks.
Statistical learning (SL) within modalities is an area of intensive research, but much less attention has been focused on how SL works across different modalities apart from demonstrating that learning can benefit from information provided in more than one modalities. We investigated visuo-auditory SL using the standard arrangement of SL paradigms. Four visual and four auditory pairs were created from 8-8 abstract shapes and distinctive sounds, respectively. Visual pairs consisted of two shapes always appearing together in a fixed relation, audio pairs were defined by two sounds always being heard at the same time. Next, strong and weak cross-modal quadruples were defined as one visual pair always occurring together with a particular auditory pair (strong) or appearing with one of two possible auditory pairs (weak). Using additional individual shapes and sounds, a large number of cross-modal six-element scenes were created with one visual pair, a single shape, one sound pair and a single sound. Adult participants were exposed to a succession such cross-modal scenes without any explicit task instruction during familiarization, and then tested in three familiarity tests: (1) visual or auditory pairs against pairs of randomly combined elements unimodally, (2) strong cross-modal quads against weak ones, and (3) visual or auditory pairs from the strong and weak quads against each other, again unimodally. We arranged relative difficulties so that in Test 1, the visual pairs were highly favored against random pairs, while choosing the auditory pairs against random sound pairs was at chance. Surprisingly, this setup caused participants choosing the weak quads significantly more often as familiar constructs in Test 2, and preferring equally strongly both the visual and auditory strong pairs over the corresponding weak pairs in Test 3. We interpreted this complex interaction through probabilistic explaining away effects occurring within the participants’ emerging internal model.
Despite recent findings of sequential effects in perceptual serial decision making (SDM) (Chopin & Mamassian 2012; Fischer & Whitney 2014), SDM is typically investigated under the assumption that the decisions in the sequence are independent or at most, are influenced by a few previous trials. We set out to identify the true underlying internal model of event statistics that drives decision in SDM by investigating and modeling a set of novel sequential 2AFC visual discrimination tasks by humans and rats. Participants solved the same decision task across trials, but experienced one shift in baseline appearance probabilities of noisy stimuli during the experiment. We found non-trivial interactions between short- and equally strong long-term effects guiding evidence accumulation and decisions in such SDM. These interactions could elicit paradoxical and long-lasting net serial effects, for example, a counterintuitive negative decision bias towards the recently less frequent element. Our findings cannot be explained by previous models of SDM that either assume a sequential integration of prior evidence, presume an implicit compensation of discrepancies between recent and long-term summary statistics, or adjust learning rates of those statistics at change points. To provide a normative explanation for the empirical data, we developed a hierarchical Bayesian model that could simultaneously represent the priors over the appearance frequencies and a potentially non-uniform noise model over the different stimulus identities. The results of simulations with the model suggest that humans are more disposed to readjust their noise model instead of updating their priors on appearance probabilities when they observe sudden shifts in the input statistics of stimuli. In general, regardless of the simplicity of the decision task, humans automatically utilize a complex internal model during SDM and adaptively alter various components of this model when detecting sudden changes in the conditions of the task.
Repeated perceptual decision-making is typically investigated under the tacit assumption that each decision is an independent process or, at most, it is influenced by a few decisions made prior to it. We investigated human sequential 2-AFC decision-making under the condition, when more than one aspect of the context could vary during the experiment: both the level of noise added to the stimulus and the cumulative base rate of appearance (how often A vs. B appeared) followed various predefined patterns. In seven experiments, we established that long-term patterns in the context had very significant effects on human decisions. Despite being asked about only the identity of the present stimulus, participants’ decisions strongly reflected summary statistics of noise and base rates collected dozens to hundreds of trials before. In addition, these effects could not be described simply as cumulative statistics of earlier trials: for example, a significant step change in base rate (a change point) could induce the same effect as a prolonged shift, while a gradual change did not induce any effect. As standard decision making models cannot explain these results, we developed a hierarchical Bayesian model that simultaneously represented the priors over the base rates and a potentially non-uniform noise model over the different stimulus identities. Based on simulations with the model, we conducted additional experiments and found that when a change occurred in the context that could be captured equally well by adjusting one or another aspects of the model, humans chose adjusting the variable that was less reliable as defined by variability in the preceding extended set of trials. In general, regardless of the simplicity of a perceptual decision-making task, humans automatically develop a complex internal model, and in the light of a detected change, they adaptively alter the component of this model that is implicitly judged to be the least reliable one.
I will present a framework and a combined empirical-computational program that explores what computation and cortical neural representation could underlie our intelligent behaviour. I will start by giving a brief summary of the fundamental logic of the framework and the main results we obtained earlier in support of the framework. Next, I will focus on three specific topics of the framework in line with the main theme of the meeting. First, exploring the limits of generalization of human statistical learning, I will show that humans readily transfer object knowledge over sensory modalities: receiving diagnostic information only in the visual or only in the haptic modality, they automatically formulate abstract object representations that generalize in the other modality. Second, I report that when comparing humans and honeybees in the same visual statistical learning task, we found striking differences despite the fact that honeybees are known to be very good visual learners. While bees internal representation underwent a marked transformation from being based on simple elementary vs. complex joint combination of visual features, they systematically failed to extract predictive information automatically from the input the way that humans naturally do. Third, in a serial visual decision making task, humans known to be influenced not only by the momentary sensory input of the trial, but also by events in the preceding trials. However, we show that a major factor of this effect is due to a long-term internal model participants develop involuntarily, which more complex than a simple evidence integrator and therefore, it modulates human decision making in a way that cannot be captured by classical models. Together these results provide a firm support to the probabilistic framework of human learning.
2017
The emergence of the concept defining a discrete object in the brain is a fundamental yet poorly understood process. In two statistical learning experiments, we show that humans can form these abstract concepts via purely visual statistics or physical interactions, which nevertheless will generalize across these two modalities. Participants saw a sequence of visual scenes composed of multiple objects. Each object consisted of abstract shapes, where object identity was only defined either by the shape co-occurrences across scenes (Exp. 1), or by the physical effort required to pull the scene apart (Exp. 2). In Experiment 1, observers learned the visual statistical contingencies across the scenes (measured with visual familiarity test), and this knowledge also generalized to their judgments as to how they would pull apart novel scenes (in pulling-apart-object test). In Experiment 2, participants learned haptic statistics across scenes: in the pulling-apart-object test they preferred easier pulling directions as defined by underlying object boundaries. Moreover, this haptic learning also biased participants’ judgments in the purely visual familiarity test. Thus, objects can be extracted solely based on visual or haptic statistics while still retaining an integrated quality that allows generalization across modalities, which is a hallmark of object-like representations.
Although an abundance of studies demonstrated human’s abilities for visual statistical learning (VSL), much fewer studies focused on the consequences of VSL. Recent papers reported that attention is biased toward detected statistical regularities, but this observation was restricted to spatial locations and provided no functional interpretation of the phenomenon. We tested the idea that statistical regularities identified by VSL constrain subsequent visual processing by coercing further processing to be compatible with those regularities. Our paradigm used the well-documented fact that within-object processing has an advantage over across-object processing. We combined the standard VSL paradigm with a visual search task in order to assess whether participants detect a target better within a statistical chunk than across chunks. Participants (N=11) viewed 4-4 alternating blocks of “observation” and “search” trials. In both blocks, complex multi-shape visual scenes were presented, which unbeknownst to the participants, were built from pairs of abstract shapes without any clear segmentation cues. Thus, the visual chunks (pairs of shapes) generating the scenes could only be extracted by tracking the statistical contingencies of shapes across scenes. During “observation”, participants just passively observed the visual scenes, while during “search”, they performed a 3-AFC task deciding whether T letters appearing in the middle of the shapes formed a horizontal or vertical pairs. Despite identical distance between the target letters, participants performed significantly better in trials in which targets appeared within a visual chunk than across two chunks or across a chunk and a single shape. These results suggest that similar to object-defined within/between relations, statistical contingencies learned implicitly by VSL facilitate visual processing of elements that belong to the same statistical chunk. This similarity between the effects of true objects and statistical chunks support the notion that VSL has a central role in the emergence of internal object representations.
Cortical circuits obey Dale’s principle: each neuron either excites or inhibits all its postsynaptic targets. There is no known principled justification for why this must be so; in fact, Dale’s principle is considered – if at all – a mere constraint in neural network models. Here we provide a novel rationale for Dale’s principle: networks with separate excitatory (E) and inhibitory (I) populations preserve the temporal relationships between their inputs, thus preventing spurious temporal correlations that could mislead spike timing-dependent plasticity (STDP). To show this, we study a recurrent firing rate network model with arbitrary nonlinear response functions. We assume that, in line with known Hebbian mechanisms at both excitatory and inhibitory synapses, the magnitudes of recurrent synaptic weights are proportional to the covariance of pre- and postsynaptic rates, while their sign is determined by the E/I identity of the presynaptic cell. We show that this connectivity pattern is both necessary and sufficient to ensure that neural circuit output will be non-sequential, if the input has no specific temporal ordering of its elements. Conversely, if there is some specific temporal ordering of inputs to different neurons, then the neural circuit output will also have sequences that reproduce those of the input. Our theory predicts the relative degree of sequentiality of V1 responses to visual stimuli with different statistics, which we confirmed in cortical recordings: stimuli that are similar in lacking temporal ordering evoke responses that differ in their sequentiality, depending on whether V1 has been adapted to them. Our results suggest a novel and unexpected connection between the ubiquitous Dale’s principle and STDP, namely that Dale’s principle acts as a control mechanism to guarantee that STDP will act only on input-driven temporal sequences, rather than on internally generated ones.
2016
How specific statistical priors do we maintain? While it is known that past stimulus statistics influences later perceptual decisions, it is unclear how such effects would interact and influence decisions across different spatial locations. To test this, we used a visual discrimination paradigm with two target locations, and two abstract shapes that could appear in varying levels of Gaussian noise. The stimulus appearance probabilities shifted from the training block (always balanced) to the test block (unbalanced). In each trial, participants reported via fixation which of the two locations the stimulus would likely to appear, and using a touchpad, they chose which shape was presented. In the test of Exp. 1, object A was equally more frequent at both locations. In the test of Exp. 2, object A was more frequent at one location, but less frequent at the other location. In Exp. 1, strong priors emerged after the shift, as if participants were compensating to maintain the overall training probabilities. In contrast, in Exp. 2, participants followed the shift in appearance probabilities with their responses. This suggests that only simple priors emerge automatically, with more complex statistics, averaging might cause visual decisions to follow local probabilities more accurately.
Despite numerous studies with simple stimuli, little is known about how low-level feature information of complex images is represented. We examined sensitivity to the orientation and position of Gabor patches constituting stimuli from three classes according to their image type:Familiar natural objects, Unfamiliar fractal patterns, and Simple circular patterns. All images were generated by re-synthesizing an equal number of Gabor patches, hence equating all low-level statistics across image types, but retaining the higher-order configuration of the original images. Just noticeable differences of perturbations in either the orientation or position of the Gabor patches were measured by 2-AFC on varying pedestal. We found that while sensitivity patterns resembled those reported earlier with simple, isolated Gabor patches, sensitivity exhibited a systematic stimulus-class dependency, which could not be accounted for by current feedforward computational accounts of vision. Furthermore, by directly comparig the effect of orientation and position perturbations, we demonstrated that these attributes are encoded very differently despite similar visual appearance. We explain our results in a Bayesian framework that relies on experience-based perceptual priors of the expected local feature information, and speculate that orientation processing is dominated by within- hyper-column computations, while position processing is based on aggregating information across hyper-columns.
There is a complex interaction between short- and long-term statistics of earlier percepts in modulating perceptual decisions, yet this interaction is not well understood. We conducted experiments, in which we independently manipulated the appearance probabilities (APs) of abstract shapes over short and long time ranges, and also tested the effect of dynamically changing these probabilities. We found that, instead of simply being primed by earlier APs, subject made decisions so that they reduced the discrepancy between recent and earlier APs. Paradoxically, this leads to favor the less frequent recent event if it was more frequent in the long past. Moreover, this compensatory mechanism did not take effect when the difference in APs between long past and recent times was introduced gradually rather than abruptly. This leads to a paradox false and lasting negative compensation with uniform APs after a momentary abrupt shift followed by a gradual return. We replicated our key human finding with behaving rats, de onstrating that these effects do not rely on explicit reasoning. Thus instead simply following the rule of gradually collected event statistics, perceptual decision making is influenced by a complex process in which statistics are weighted by significance due to detected changes in the environment.
It is commonly assumed that humans learn generative or discriminative representations of the sensory input depending on task context (e.g. Hsu & Griffiths, 2010). Following our earlier findings (Orban et al., 2008), we propose that humans always form generative models based on the statistics of the input. To test this proposal, we investigated whether a learned internal model of the visual input would automatically incorporate task-irrelevant dimensions, and whether a generative model is formed even when the task requires only a simpler, discriminative representation. Participants (N=30) were presented with circle ensembles of varying mean size and standard deviation (SD). Their task was to estimate one of these parameters throughout the experiment, making the other dimension task-irrelevant. Unbeknown to the participants, the input formed two implicit categories across trials, one with small means and large SDs, and the second with large means and small SDs. Participants showed the same significant regression to the mean bias in either dimension both during the estimation task and after a categorization along the task-irrelevant dimension. Thus, even in a restricted or discriminative context, humans implicitly form a generative model of the distribution of the data, which model automatically influences their subsequent decisions.
It has been suggested recently that the extent of learning in perceptual tasks can be predicted well from the initial performance according to a Weber-like law. However, the exact relationship between initial thresholds and the amount of learning and the link between learning and generalization still remained unclear. In three perceptual learning paradigms, we tested (1) how initial thresholds influence learning, (2) how the amount of learning influences generalization, and (3) how general these relationships are across different paradigms of perceptual learning. Using a 5-day training protocol in each paradigm, separate groups of observers were trained to discriminate around two different reference values: at 73 or 30% in contrast, at 45 or 15 degrees in orientation, and at 88 or 33 dots in magnitude discrimination task. In each paradigm, initial thresholds were significantly higher at the high reference (73% contrast, 45 degrees, and 88 dots) than those at the low reference (ps< 0.05). Within conditions in each paradigm, we found strong correlations between subjects' initial threshold and their percent improvement, (rs=0.63-0.82, ps< 0.01), but their relationship did not conform the proposed Weber-like law. In contrast, across conditions in each paradigm, both the average absolute improvement and the mean percent improvement confirmed the Weber-like relationship showing no difference in percent improvement between the conditions (Bayes Factors= 2-2.3). Finally, generalization of learning was proportional to the amount of learning (linear regression slopes= 0.74-0.92, r2s= 0.45-0.83). This pattern of result suggests that (1) individual variations in perceptual learning are not related to the learning process but to other factors such as motivation, (2) regardless of individual differences and testing paradigms, the amount of perceptual learning conditioned on visual attributes is proportional to the initial thresholds following a Weber-like law, and (3) generalization is linearly proportional to the amount of learning within the task.
Coding of visual attributes in human vision has traditionally been researched with simple stimuli (e.g., Gabor patches), presented either in isolation or in simple lattice-like arrangements. Consequently, little is known about how low-level feature information is represented with complex and naturalistic images under natural-like viewing conditions. In severalexperiments, we examined coding of the orientation and position of Gabor patches constituting stimuli from three classes according to their image type: 1) Familiar natural objects,2) Unfamiliar fractal patterns, and 3) Simple circular patterns. Naturalistic-like stimuli were generated by decomposing images from each class with a bank of Gabor wavelets, which were then re-synthesized using an equal number of oriented Gabor patches, equating all low-level statistics across image types, but retaining the higher-order configuration of the original images. Using a 2AFC paradigm, we measured the justnoticeable difference of perturbations to either the orientation or position of the Gabor patches. We found that for both orientation and position noise, sensitivity across increasing levels of pedestal noise resembled that found with simple, isolated Gabor patches (Morgan et al., 2008;Li et al., 2004) validating our stimuli and method. However, we also found that sensitivity systematically depended on the familiarity and the complexity of the stimulus class, which could not be accounted for by current computational accounts of encoding. As an alternative, we propose a Bayesian framework that utilizes an experience-based perceptual prior of the expected local orientations and positions. Furthermore, using this unified method, we could directly compare orientation and position coding and show that they are encoded differently. We speculate that sensory processing of orientation is dominated within hyper-columns, well approximated by an intrinsic hard threshold operating among orientation columns to discount noise, while sensory processing of position is based on aggregating information across hyper-columns.
Optimal estimation from correlated, as opposed to uncorrelated, samples requires different strategies. Given the ubiquity of temporal correlations in the visual environment, if humans are to make decisions efficiently, they should exploit information about the correlational structure of sensory samples. We investigated whether participants were sensitive to the correlation structure of sequential visual samples and whether they could flexibly adapt to this structure in order to approach optimality in the estimation of summary statistics. In each trial, participants saw a sequence of ten dots presented at different locations on the screen which were either highly correlated (r = 0.7) or uncorrelated (in two separate blocks of 260 trials), and were asked to provide an estimate of the mean location of the dots. In the high correlation block, participants showed a trend towards overweighting the first and last samples of the sequence, in accordance with the optimal strategy given correlated data. In contrast, when exposed to uncorrelated inputs, the weights that participants assigned to each sample did not differ significantly from the optimal uniform allocation. Thus, it appears that humans are sensitive to the correlational structure of the data and can flexibly adapt to it so that their performance approximates optimality.
2015
Probabilistic models of perception posit that subjective uncertainty related to any perceptual decision is represented in the cortex via probability distributions that encode features in a task-relevant, distributed manner (e.g. Probabilistic Sampling PS, Fiser et. al 2010). According to PS, to achieve any decision, this posterior distribution needs to be sampled through time. However, traditional evidence integration (EI) models also assume sequential integration of external sensory information over time, and they can predict the accuracy in such a task. Which process shapes the trial-by-trial time course of human behavior? In a series of human behavioral experiments, we found that both processes are present in the time-course of a perceptual judgment and that their mutual influence on behavior is flexible. We used an estimation-based variant of the classical random dot motion (RDM) task, where in each trial, participants (N=14) reported their best estimate of stimulus direction and their subjective uncertainty about their decision simultaneously. The objective uncertainty for each trial was chosen locally from two coherence values (30% vs. 55%), and globally across trials by either blocking or randomly interleaving the trial-by-trial coherence values. Stimuli were presented for varying length of time the RDM for durations between 100ms and 1.5sec. Confirming our analytical derivations, we found a significant and positive overall correlation between error and subjective uncertainty beyond 300-500 msec as a function of time in all participants. As such positive correlations are the hallmark of PS and cannot be caused by EI, these results indicate that, indeed, probabilistic inference processes dominate the latter part of decision making. Specifically, by splitting up trials in RDM duration, we found a marked decrease in both error-uncertainty correlation and absolute error within the first 300-500ms, indicating EI, followed by a significant increase throughout the remaining time, indicating PS. Importantly, the transition between these segments shifted as a function of both local and global objective uncertainty. Thus, we propose that in perceptual decision making based on dynamic stimuli with limited information perceptual process is not simply noisy evidence integration, but rather a probabilistic inference process. Moreover, this process in perceptual judgments follow a pattern that is related to that found during learning in an uncertain environment: When the global uncertainty is high, PS begins dominating earlier in time if local uncertainty is low compared to when local uncertainty is high. In contrast, when the global uncertainty is low – PS takes over at the same time regardless of the level of local signal uncertainty.
Current models of human visual decision making based on sequentially provided samples posit that people make their next decision by unconsciously compensating the statistical discrepancy between measures collected in the long past and those collected very recently. While this proposal is compelling, it does not qualify as a rigorous model of human decision making. In addition, recent empirical evidence suggests that human visual decision making not only balances long- and short-term summary statistics of sequences, but in parallel, it also encodes salient features, such as repetitions, and in addition, it relies on a generic assumption of non-discriminative flat prior of events in the environment. In this study, we developed a normative model that captures these characteristics. Specifically, we built a constrained Bayesian ideal observer with a generative model having features as follows. First, data is generated randomly but not necessarily independently depending on its parameter selection. Second, the system has a memory capacity denoted by a small window size = t, and a world representation denoted by a large window size = T, the latter reflecting the observer’s belief of the volatility of the world, i.e. the extent to which changes should be represented. Third, events can be described with pi appearance probability, which is not constant in time but changes according to a Markovian update, and it has an initial strong peak at 50%. Fourth, observations are noisy so that the observer can collect only limited amount of information (𝛾i) from each sample image. We implemented the above model and training on human data, we determined the optimal parameters for T, t, and inferred the evolving pi for each subject. Our model could capture the behavior of human observers, for example their deviation from binomial distribution based on T, and t, and the negative correlation between recent and past decisions.
Although it is widely accepted that both summary statistics and salient patterns affect human decision making based on temporally varying visual input, the relative contributions and the exact nature of how these aspects determine human judgment are unclear and controversial, often discussed under the labels of priming, adaptation, or serial effects. To tease apart the role of the various factors influencing such decision making tasks, we conducted a series of 7 adult behavioral experiments. We asked subjects to perform a 2-AFC task of judging which of two possible visual shapes appeared on the screen in a randomly ordered sequence while we varied the long- and short-term probability of appearance, the level of Gaussian pixel noise added to the stimulus, and the ratio of repetitions vs. alternations. We found that the quality of the stimulus reliably and systematically influenced the strength of influence by each factor. However, instead of a simple interpolation between long-term probabilities and veridical choice, different pairings of short- and long-term appearance probabilities produced various characteristic under- and over-shootings in choice performances ruling out earlier models proposed for explaining human behavior. Independent control of base probabilities and repetition/alternation revealed that despite the two characteristics being correlated in general, repetition/alternation is a factor independently influencing human judgment. In addition, we found that human performance measured by correct answers and by reaction times (RT) yield opposing results under some conditions indicating that RT measures tap into motor rather than cognitive components of sequence coding. Our results can be captured by a model of human visual decision making that not only balances long- and short-term summary statistics of sequences, but in parallel also encodes salient features, such as repetitions, and in addition, relies on a generic assumption of non-discriminative flat prior of events in the environment.
We investigated how well people discriminate between different statistical structures in letter sequences. Specifically, we asked to what extent do people rely on feature-based aspects vs. lower-level statistics of the input when it was generated by simple or by more hierarchical processes. Using two symbols, we generated twelve-element sequences according to one of three different generative processes: a biased coin toss, a two-state Markov process, and a hierarchical Markov process, in which the states of the higher order model determine the parameters of the lower order model. Subjects performed sequence discrimination in a 2-AFC task. In each test trial they had to decide whether two sequences originated from the same process or from different ones. We analyzed stimulus properties of the three sets of strings and trained a machine learning algorithm to discriminate between the stimulus classes based either on the identity of the elements in the strings or by a feature vector derived for each string, which used 13 of the most common features split evenly between summary statistics (mean, variance, etc.) and feature-based descriptors (repetitions, alternations). The learning algorithm and subjects were trained and tested on the same sequences to identify the most significant features used by the machine and humans, and to compare the two rankings. Not only there was a significant agreement between the ranks of features for machine and humans, but both used a mixture of feature-based and statistical descriptors. The two most important features for humans were ratio between relative frequencies of symbols and existence of repeating triples. We also found a consistent asymmetry between repetition and alternation as repetitions of length three or higher were consistently ranked higher than alternations of the same length. We found that, without further help, humans did not take into account the complexity of the generative processes.
People rapidly and precisely extract summary statistics (e.g. mean and variance) of visually presented ensembles, and such statistics represent an essential part of their internal representation reflecting their environment. Recently, we reported that humans’ behavior in perceptual decision making task complies with the proposal that they handle simple visual attributes in a sampling-based probabilistic manner (Popovic et al. Cosyne 2013, VSS 2013; Fiser et al. ECVP 2013; Christensen et al. VSS 2014, ECVP 2014). In this study, we tested whether such probabilistic representations also may underlie the assessment of visual summary statistics. In each trial, subjects saw a group of circles (N=2…10, randomly chosen) of varying sizes and had to estimate either the mean or variance of sizes of the ensemble or the size of one individual circle from the group specified after the figure with the group was taken off the screen. In addition, they also reported their subjective confidence about their decisions on a trial-by-trial basis. Trials from the three tasks were tested either intermixed or by presenting them in blocks, separately. Stimuli were also presented at nine different durations (50, 75, 100, 133, 167, 200, 300, 400, or 600 msec). In accordance with previous results, participants could estimate correctly the mean, the variance and size of an element within the ensembles. Interestingly, mean estimation improved significantly as a function of the number of circles in the display (p < 0.001). More importantly, we found and increasing correlation between error and uncertainty as a function of presentation time, which is the hallmark of sampling-based probabilistic representation. Thus such probabilistic representation is not used exclusively for the simplest visual attributes, such as orientation, speed of small dots, but they also apply to representing more abstract kind of summary statistics.
Although visual rule learning has been viewed as a potential candidate of how humans develop higher-order internal representations, typical rule-learning experiments have focused on the ability to extract abstract rules defined by element repetition rather than regularities based on feature dimensions. To link rule learning to the natural task of visual recognition, we investigated learning rules that were based on size regularities of visual objects perceived in a graphically generated three-dimensional layout. We found that adult subjects could extract the classical AAB type of rules based on size relations, and that the extracted rule was defined by the perceived 3-dimensional interpreted size of the objects rather than by the actual 2-dimensional extent of their images. Moreover, the extracted rule generalized not only to new displays with never-before-seen objects, but also to new 2-dimensional contexts where the original 3D perceptual constraints were not present at all. These results extend the generality of rule learning in vision supporting the view that the extracted rules are not purely semantic but incorporate mid-level perceptual information, yet at the same time, they are abstract enough to apply across wide range of contexts.
Apart from the raw visual input, people’s perception of temporally varying ambiguous visual stimuli is strongly influenced by earlier and recent summary statistics of the sequence, by its repetition/alternation structures, and by the subject’s earlier decisions and internal biases. Surprisingly, neither a thorough exploration of these effects nor a framework relating those effects exist in the literature. To separate the main underlying factors, we ran a series of nine 2-AFC visual decision making experiments. Subjects identified serially appearing abstract shapes in varying level of Gaussian noise (uncertainty), appearance probabilities and repetition-alternation ratio. We found a) an orderly relationship between appearance probabilities on different time-scales, the ambiguity of stimuli and perceptual decisions; b) an independent repetition/alternation effect, and c) a separation of bias effects on RT and decision, suggesting that only the latter is appropriate for measuring cognitive effects. We confirmed our main human results with behaving rats making choices based on luminance between stimuli appearing at different locations. These findings are compatible with a probabilistic model of human and animal perceptual decision making, in which not only decisions are taken so that short-term summary statistics resemble long-term probabilities, but higher order salient structures of the stimulus sequence are also encoded.
Past experience strongly guides sensory processing and influences every perceptual decision. Yet, due to contradictory findings in the literature, the exact pattern of these effects is unclear and a convincing general computational framework underlying these effects is still missing. Even in the simplest version of the problem, making a forced choice between two hypotheses based on noisy sequential input, the field is divided over how basic statistics of the input (e.g. appearance frequencies) and various significant patterns (e.g. repetition) jointly determine the observer’s behavior. We used the above model problem in 7 experiments to tease apart the relative contributions of each effect on human sequential decision making. Observers performed a 2-AFC decision making (“Which of the two shapes is seen?”), while we independently modulated the level of pixel-noise, the appearance frequency of the elements coming from the two classes at two different time scales, and the ratio of repetition/alternation in the sequence. We found that the noise level of the stimulus systematically modulated the strength of each contributing factor to decision making. However, instead of a simple interpolation between long-term probabilities and veridical choice as it would be predicted by adaptation or priming, different pairings of short- and long-term appearance probabilities produced various characteristic under- and over-shootings in choice performances. This rules out a number of earlier models proposed for explaining human behavior in such tasks. We also found that human performance measured by correct answers and by reaction times yielded opposing results under some conditions indicating that RT measures tap into motor rather than cognitive components of sequence coding. By controlling the base-rate probabilities and repetitions/alternations independently, we also observed that despite the two measures being correlated in general, repetition/alternation is a factor independently influencing human judgment. To assess the generality of our findings, we run behavioral studies with adult rats asking them to choose between two full-field stimuli of different brightness. We found that rats replicated the striking results of humans, by choosing the frequent stimulus of recent past fewer times under high uncertainty after experience with particular long-term appearance statistics. Through simulations, we confirmed that our results can be captured by a probabilistic model of human visual decision making that balances long- and short-term summary statistics of sequences, and in parallel, also encodes salient features, such as repetitions in the sequence.
Although orientation coding in the human visual system has been researched with simple stimuli, little is known about how orientation information is represented while viewing complex images. We show that, similar to findings with simple Gabor textures, the visual system involuntarily discounts orientation noise in a wide range of natural images, and that this discounting produces a dipper function in the sensitivity to orientation noise, with best sensitivity at intermediate levels of pedestal noise. However, the level of this discounting depends on the complexity and familiarity of the input image, resulting in an image-class-specific threshold that changes the shape and position of the dipper function according to image class. These findings do not fit a filter-based feed-forward view of orientation coding, but can be explained by a process that utilizes an experience-based perceptual prior of the expected local orientations and their noise. Thus, the visual system encodes orientation in a dynamic context by continuously combining sensory information with expectations derived from earlier experiences.
Previous studies have reported several factors, including prior knowledge, past experience, immediately preceding events, and rate of event repetitions that influence humans’ ability to predict and perceive sequentially occurring probabilistic events. However, many of these factors are correlated and most earlier studies made little effort to disentangle their confounding effects. I will present a series of human behavioral experiments, in which we systematically inspected the separate and joint effects of these factors within a simple visual perceptual paradigm. We found that, rather than simply balancing past and present statistics, the best model describing human performance is probabilistic and it assumes a parallel working of several factors: a) reliance on prior statistical knowledge of the sequence as a function of stimulus uncertainty, b) a “regression to the mean” kind of effect that could reflect a general strategy of non-commitment, and c) an independent short-term repetition effect which influences performance asymmetrically.
2013
Recent work has established the importance of top-down influences on early sensory processing. These influences are alternatively taken as representing task context, attention, expectation, working memory and motor commands (Gilbert & Li, 2013). At the same time, top-down influences have been recognized as essential for supporting probabilistic inference (Lee & Mumford, 2003). Here, we combine the latter idea with the recent hypothesis that the brain implements probabilistic inference using a neural sampling-based representation (Fiser et al 2010) and show that a normative account can indeed explain several disparate empirical observations on the effect of task context, expectation and attention on neuronal response gain and interneuronal response correlation. In particular, we show for a classic 2AFC task, that neural sampling can explain the task-dependent correlations seen by Cohen & Newsome (2008) and the choice probability time-course observed by Nienborg & Cumming (2010). Furthermore, we propose that top-down attention due to unequal rewards acts as a loss-calibration of the sampling approximation to the true posterior and show that this hypothesis entails an increase in response magnitude for neurons at the attended location as well as a decrease in noise correlations (Cohen & Maunsell, 2009, Mitchell & Reynold, 2009). Unlike previous accounts which assumed these effects to be the source for an improved psychophysical performance at the attended location, in our account, they are a consequence of probabilistic inference with changing constraints.
Directional selectivity (DS) is known to increase significantly in ferrets during two weeks after eye opening and it has been shown to strongly depend on visual experience (Li et al. 2008, Nature). Such selectivity to features of the input is traditionally assumed to indicate the functional maturity of the visual system, however, this assumption has not been confirmed directly. Recently, a measurement for assessing functional maturity has been put forth by Berkes et al. (2011, Science) based on the idea that a mature visual system is optimized for probabilistically encoding natural stimuli. They use Kulback-Leibler divergence (KL) to quantify dissimilarities in the statistical structure of multi-neuron firing patterns in V1 of awake ferrets acquired under different stimulus conditions. The distribution of firing patterns acquired in complete darkness (spontaneous activity) reflects the prior probability distribution over visual features that is unconstrained by visual input. According to the probabilistic approach, the more the distribution of spontaneous activity is similar to the distribution of average activity evoked by naturalistic stimuli, the more the visual system is adapted to the statistics of the visual environment. Berkes et al. (2011) have shown that the dissimilarity of these two distributions monotonically decreases with animal age, supporting the notion of gradual maturation of the system. However, due to constraints of the experimental design it was not possible to determine the role that visual experience plays in this optimization process. In the present study, we explored both the role of experience in this maturation, and the relationship between KL and the more commonly used measure of functional maturity based on direction selectivity. Specifically, we acquired measurements of spontaneous and visually evoked activity in awake, and directional selectivity tuning in anesthetized visually naïve ferrets (mean age p30) using extracellular 16 channel microwire array electrodes chronically implanted into V1. Immediately after acquiring these measurements, the animals were randomly assigned to one of three experimental conditions: (1) visual training with drifting gratings while anesthetized, (2) visual training with naturalistic movies while anesthetized or (3) no visual training while awake. After 12 hours of training in the assigned experimental condition, both measurements were acquired again. This experimental design allowed us to correlate the two measurements of visual maturity, and explore the role of visual experience in the process of optimizing an immature visual system to the statistics of the visual environment.
In the last two decades, a quiet revolution took place in vision research, in which Bayesian methods replaced the once-dominant signal detection framework as the most suitable approach to modeling visual perception and learning. This tutorial will review the most important aspects of this new framework from the point of view of vision scientists. We will start with a motivation as to why Bayes, then continue with a quick overview of the basic concepts (uncertainty and probabilistic representations, basic equations), moving on to the main logic and ingredients of generative models including Bayesian estimation, typical generative models, belief propagation, and sampling methods. Next we will go over in detail of some celebrated examples of Bayesian modeling to see the argument and implementation of the probabilistic framework in action. Finally, we will have an outlook as to what the potential of the generative framework is to capture vision, and what the new challenges are to be resolved by the next generation of modelers.
In models of perceptual decision making within the classical signal processing framework (e.g. integration-to-bound), time is used to accumulate evidence. In probabilistic, sampling-based frameworks, time is necessary to collect samples from subjective posterior distributions for the decision. Which role is dominant during perceptual decisions? We have analytically derived the progression of the error and subjective uncertainty in time for these two models of decision making, and found that they show a very differently evolving pattern of the correlation between subjects’ error and their subjective uncertainty. Under sampling, after a brief initial period, the correlation always increases monotonically to an asymptote with this increase continuing long after the error itself has reached its asymptote. In contrast, integration-to-bound shows increasing or decreasing changes in correlation depending on the posterior’s kurtosis, and with additive behavioral noise, the correlation decreases. We conducted a decision making study where subjects had to perform time-limited orientation matching and report their uncertainty about their decisions, and found that the results confirmed both predictions of the sampling-based model. Thus, under typical conditions, time in decision making is mostly used for assessing what we really know and not for gathering more information.
The developmental increase in similarity between spontaneous (SA) and average stimulus-evoked activity (EA) in the primary visual cortex has been suggested to reflect a progressive adaptation of the animal’s internal model to the statistics of the environment, a hallmark of probabilistic computation in the cortex (Berkes et al, 2011). Still, this gradual adaptation could be due to genetically controlled developmental processes that have little to do with the animal’s visual experience. To clarify this issue, we disrupted normal visual experience of N=16 ferrets of different ages (P30-P120) so that the animals perceived only diffuse light through their eyelids up to the moment of data collection. We measured neural activity from the superficial layers of V1 and compared SA and EA to those in normally reared controls. Furthermore, we extended the original analysis using maximum entropy models that control not only for the effects of single unit firing rates, but also for the population firing rate distribution which could confound measures of functional connectivity that we use as a measure of learning. The general statistics of V1 activity in lid-sutured animals developed very similarly to controls confirming that withholding natural visual experience does not abolish the general development of the visual system. However, while in the control animals SA was completely similar to EA evoked by natural stimuli and significantly less similar to EA evoked by noise, in lid-sutured animals this specificity to natural inputs disappeared, and the match between SA and EA for natural inputs became incomplete. Our novel analysis further confirmed that learning drives the increase of similarity between SA and EA in the oldest control adults. These results suggest that while intrinsic development of visual circuitry is controlled by developmental factors, learning from visual experience is crucial for the emergence of a complete match between SA and EA.
The effects of time on human decision-making are well known, yet, the precise mechanisms underlying these effects remain unclear. Under the classic signal processing framework (e.g. integration-to-bound) the passing of time allows for accumulation of evidence, parametric models of probabilistic neural representations (e.g. PPC) hold that time is used for averaging internal noise for a better estimate of firing rates, while non-parametric, sampling-based models posit that time influences the collection of samples from subjective posterior distributions. These models provide different predictions about the nature and temporal evolution of subjects’ errors and the correlation between their error and their subjective uncertainty. We have analytically derived the progression of error and subjective uncertainty in time for the three models under a decision-making scenario, and found characteristic differences in their behavior. Under sampling, after a possible transient decrease depending on the kurtosis of the posterior, the correlation always increases monotonically to an asymptote. Importantly, this increase continues long after the error itself has reached its asymptote. In contrast, both integration-to-bound and PPC models can show increasing or decreasing changes in correlation depending on the posterior’s kurtosis, and when noise corrupts the posterior, this correlation decreases. We conducted a decision-making study in which subjects performed time-limited orientation matching and reported their uncertainty about their decisions, and found that the results confirmed both predictions of the sampling-based model. As these characteristics are not present in parametric and integration-to-bound models, the present results lend strong support to a novel use of time in decision-making: collecting samples from otherwise static internally represented distributions.
The developmental increase in similarity between spontaneous (SA) and average stimulus-evoked activity (EA) in the primary visual cortex has been suggested to reflect a progressive adaptation of the animal’s internal model to the statistics of the environment (Berkes et al., Science 2011). However, it is unknown how much of this adaptation is due to learning or simple developmental programmes. If learning plays a role, it makes two predictions: changes in the functional connectivity between neurons should underlie the changes seen during development, and these developmental changes should be experience-dependent. Neither of the two has been satisfyingly tested, if at all, in previous work. Here we address the issue of functional coupling by novel analyses with maximum entropy models (Schneidman et al., Nature 2006) that control not only for the effects of single unit firing rates, but also for the population firing rate distribution which could otherwise confound measures of functional connectivity (Okun et al., SfN, 2011). We show that functional connectivity plays an increasing role during development in shaping both SA and EA, and in particular that it significantly contributes to the similarity of SA and EA. Moreover, we directly asses the role of experience by comparing neural activities recoded in animals reared with their lids sutured (LS) to those recorded in normally developing controls. Neural activity in LS animals was qualitatively similar to that in controls, confirming that withholding natural visual experience does not abolish the general development of the visual system. However, there were some key differences: the match between SA and EA remained incomplete, and the specificity of this match for natural images was significantly reduced in LS animals. Taken together, these results strongly suggest that learning in the cortex crucially contributes to the similarity between SA and EA.
Human and animal studies suggest that human perception can be interpreted as probabilistic inference that relies on representations of uncertainty about sensory stimuli suitable for statistically optimal decision-making and learning. It has been proposed recently that the way the brain implements probabilistic inference is by drawing samples from the posterior probability distribution, where each sample consists of instantaneous activity of a population of neurons (Fiser et al, 2010). However, there is no experimental evidence thus far, showing that an internal representation of uncertainty can extend to low-level sensory attributes, nor that humans use sampling-based representations in perceptual judgment tasks. To address these questions, we created an orientation-matching task in which we measured both subjects’ performance and their level of uncertainty as they matched orientation of a randomly chosen element of the previously presented stimulus. Stimuli consisted of 2-7 differently oriented line segments shown spaced evenly on a circle extending 2 degrees of the visual field. In response to the first question, we found that subjects’ performance and subjective report of uncertainty were significantly correlated (r=0.37, p<.001) and that this correlation was independent of the number of oriented line segments shown. To address the second question, we varied the stimulus presentation time trial-to-trial to influence the number of samples available before making a judgment. Since samples are drawn sequentially, the prediction of the sampling-based representations is that precision of representing uncertainty will depend on the time available independent of the recorded performance. We found that decreasing the presentation time results in a significant decrease of the error-uncertainty correlation (p<0.05) while the performance levels remain constant. Thus, limiting the presentation time influences the reliability of uncertainty representation specifically, in agreement with sampling-based representations of uncertainty in the cortex, and in contrast with the predictions of other probabilistic representations.
Most computational models of the responses of sensory neurons are based on the information in external stimuli and their feed-forward processing. Extrasensory information and top-down connections are usually incorporated on a post-hoc basis only, e.g. by postulating attentional modulations to account for features of the data that feed-forward models cannot explain. To provide a more parsimonious account of perceptual decision-making, we combine the proposal that bottom-up and top-down connections subserve Bayesian inference as the central task of the visual system (Lee & Mumford 2003) with the recent hypothesis that the brain solves this inference problem by implementing a sampling-based representation and computation (Fiser et al 2010). Since the sampling hypothesis interprets variable neuronal responses as stochastic samples from the probability distribution that the neurons represent, it leads to the strong prediction that dependencies in the internal probabilistic model that the brain has learnt will translate into observable correlated neuronal variability. We have tested this prediction by implementing a sampling-based model of a 2AFC perceptual decision-making task and directly comparing the correlation structure among its units to two sets of recently published data. In agreement with the neurophysiological data, we found that: a) noise correlations between sensory neurons dependent on the task in a specific way (Cohen & Newsome 2008); and b) that choice probabilities in sensory neurons are sustained over time, even as the psychophysical kernel decreases (Nienborg & Cumming 2009). Since our model is normative, its predictions depend primarily on the task structure, not on assumptions about the brain or any additional postulated processes. Hence we could derive additional experimentally testable predictions for neuronal correlations, variability and performance as the task changes (e. g. to fine discrimination or dynamic task switching) or due to perceptual learning during decision-making.
In contrast with the traditional deterministic view of perception, a number of recent studies have argued that it is best captured by probabilistic computations. A crucial aspect of real-world scenes is that conflicting cues render stimuli ambiguous which results in multiple hypotheses being compatible with the stimuli. Although the effects of perceptual uncertainty have been well-characterized on perceptual decisions, the effects on learning have not been studied. Statistically optimal learning requires combining evidence from all alternative hypotheses weighted by their respective certainties, not only from the most probable interpretation. We tested whether human observers can learn about and make inferences in such situations. We used an unsupervised visual learning paradigm, in which ecologically relevant but conflicting cues gave rise to alternative hypotheses as to how unknown complex multi-shape visual scenes should be segmented. The strength of conflicting segmentation cues, “high-level” statistically learned and “low-level” grouping features of the input, were systematically manipulated in a series of experiments, and human performance was compared to Bayesian model averaging. We found that humans weighted and combined alternative hypotheses of scene description according to their reliability, demonstrating an optimal treatment of uncertainty in learning. These results capture not only the way adults learn to segment new visual scenes, but also the qualitative shift in learning performance from 8-month-old infants to adults. Our results suggest that models of perceptual learning that evaluate a single hypothesis with the “best explanatory power” instead of model averaging, are not sufficient for characterizing human visual learning
2012
Despite ample behavioral evidence for probabilistic learning in the brain, the neural underpinnings of this process remain unclear. It has been recently hypothesized that spontaneous activity in primary sensory areas could be a marker for this learning process (Fiser et al, 2010). In this view, the increase in similarity between spontaneous and stimulus-evoked activity over development reflects a progressive adaptation of the animal’s internal model to the statistics of the environment. Indeed, recordings in the developing visual system of the ferret confirmed that the structure of spontaneous activity gradually adapts with age to that of visually evoked activity and that this adaptation is specific to natural stimuli (Berkes et al, 2011). However, this finding leaves open the option that the gradual adaptation is due to genetically controlled developmental processes that has little to do with the animal’s visual experience. One test of the theory is to disrupt visual experience and measure whether this intervention reduces the similarity between spontaneous and stimulus evoked activity for naturalist stimuli. To perform such a test, we collected neural activity of the primary visual cortex of N=14 lid-sutured awake behaving ferrets at three different age groups of P44, P80 and P120. The animals had no visual experience only diffuse light through their eye lids up to the moment of data collection. Extracellular multi-unit activity was collected with a 16 channel line electrode from the superficial layers of V1. We analyzed the spontaneous and stimulus evoked activity and compared them to normally reared controls. The analysis revealed that, while in control animals in the oldest age group spontaneous activity is most similar to activity evoked by natural stimulation, in lid-sutured animals responses to natural scenes show the same degree of similarity as those evoked by noise. The effect is specific to this distinction, as the general statistics of V1 activity in lid-sutured animals develop very similarly to controls. Overall, these results confirm that while intrinsic development of visual circuitry is strongly controlled by developmental factors, learning is one of the driving forces behind the observed increases in similarity between the spontaneous and stimulus evoked activity.
Over development, spontaneous activity (SA) in primary visual cortex (V1) becomes increasingly similar to stimulus evoked activity (EA) (Berkes et al, Science 2011). This increasing similarity has been taken to reflect a progressive adaptation of the animal’s internal models to the statistics of the environment (Berkes et al, 2011). An alternative interpretation (Okun et al, Soc Neurosci Abstr 2011) suggests these effects can be obtained with a simple model that only matches the mean firing rate on each electrode and the distribution of population rates, but not detailed patterns of pairwise correlations between neurons. Hence, the increased similarity between SA and EA in adult animals could be simply a reflection of changes in these network properties, without necessarily implying the learning of a model of the environment (Okun et al, 2011). To test this hypothesis directly, we created surrogate data by fitting maximum entropy models to the original data recorded in ferret V1 (Berkes et al, 2011) matching the mean firing rates of all individual channels and the distribution of population rates, as suggested by Okun et al. We then compared these surrogate data to the original. In line with the analysis of Okun et al (2011), we found that similar results to those described by Berkes et al (2011) could be obtained if the true response distributions were only constrained by single neuron firing rates and population rate distributions. However, in contrast to the prediction of Okun et al (2011), the true response distributions were found to become increasingly dissimilar from their surrogate versions, and this difference was important in matching SA and EA. In a parallel submission (Fiser et al) we also report that in lid sutured animals the specificity of the match between SA and EA to natural scenes is disrupted, suggesting a direct role of visual experience in its development. Overall, our results support the view that learning is indeed one of the factors driving the increase in similarity between spontaneous and evoked activity in primary visual cortex.
Increasing body of psychophysical evidence supports the view of human perception as probabilistic inference that relies on representations of uncertainty about sensory stimuli and that is appropriate for statistically optimal decision making and learning. A recent proposal concerning the neural bases of these representations posits that instantaneous neural activity corresponds to samples from the probability distribution it represents. Since these samples are drawn sequentially, a crucial implication of such sampling-based representations is that precision of representing uncertainty will depend on the time available. To test this implication we created an orientation- matching task in which the subjects were presented several differently oriented line segments. We measured both subjects’ performance and their level of uncertainty as they matched the orientation of a randomly chosen element from the previously presented stimulus. We varied the stimulus presentation time trial-to-trial to influence the number of samples available before making a decision. We found that subjects’ performance and uncertainty judgment were correlated. Importantly, with decreasing the presentation time this correlation decreased significantly while the performance levels did not change. Thus, limiting the available time specifically influences the reliability of uncertainty representation, in agreement with sampling-based representations of uncertainty in the cortex
It is well-documented that neural responses in sensory cortices are highly variable: the same stimulus can evoke a different response on each presentation. Traditionally, this variability has been considered as noise and eliminated by using trial-averaged responses. Such averaged responses have been used almost exclusively for characterizing neural responses and mapping receptive fields with tuning curves, and accordingly, most computational theories of cortical representations have neglected or focus on unstructured Poisson-like aspects of neural variability. However, the large magnitude, characteristic spatio-temporal patterns and systematic, stimulus-dependent changes of neural variability suggest it may play a major role in sensory processing. We propose that sensory processing and learning in humans and other animals is probabilistic following the principles of Bayesian inference, and neural activity patterns represent statistical samples from a probability distribution over visual features. In this representational scheme, the set of responses at any time in a population of neurons in V1 represents a possible combination of visual features. Variability in responses arises from the dynamics that evokes population patterns with relative frequencies equal to the probability of the corresponding combination of features under the probability distribution that needs to be represented. Consequently, the average and variability of responses encode different and complementary aspects of a probability distribution: average responses encode the mean, while variability and co-variability encode higher order moments, such as variances and covariances, of the distribution. We developed a model derived from this sampling-based representational framework and showed how it can account for the most prominent hitherto unexplained features of neural variability in V1 related to changing variability and the pattern of correlations without necessarily changing mean responses. Besides providing the traditional mean responses and ting curves, the model replicates a wide range of experimental observations on systematic variations of response variability in V1 reported in the literature. These include the quenching of variability at stimulus onset measured either by membrane potential variability or by the Fano factor of spike counts, contrast-dependent and orientation-independent variability of cell responses, contrast-dependent correlations, and the close correspondence between spontaneous and evoked response distributions in the primary visual cortex. Crucially, current theories of cortical computations do not account for any of these non-trivial aspects of neural variability. The framework also makes a number of key predictions related to the time-dependent nature of the sampling-based representation. These results suggest that representations based on samples of probability distributions provide a biologically feasible new alternative to support probabilistic inferential computations of environmental features in the brain based on isy and ambiguous inputs.
Although visual statistical learning (VSL) has been established as a method for testing implicit knowledge gained through observation, little is known about the mechanisms underlying this type of learning. We examined the role of sleep in stabilization and consolidation of learning in a typical VSL task, where subjects observed scenes composed of simple shape combinations according to specific rules, and then demonstrated their gained familiarity of the underlying statistical regularities. We asked 1) whether there would be interference between learning regularities in multiple VSL tasks within close spatial and temporal proximity even if the shapes used in the tasks were different, and 2) whether sleep between interfering conditions could stabilize and consolidate the learning rules, improving performance. Subjects completed four separate VSL learning blocks, each containing scenes composed of different shapes: Learning A and B were presented sequentially, Learning B and C were separated temporally by two hours, and Learning C and D were separated by a period of similar length in which subjects either took a nap which included or excluded REM sleep, or remained awake, either quietly or actively. Familiarity tests with the four structures were conducted following Learning D. If sleep blocks interference, we would expect to see interference between Learning A and B, and not between Learning C and D. If sleep increases learning, performance would be best on the test of Learning D. We found indications of interference between Learning A and B, but only in the non-REM nap group. Also, a significantly improved performance on the Learning D familiarity test was found, but only in the REM nap group. Thus, knowledge gained by VSL does interfere despite segregation in shape identity across tasks, a period of stabilization can eliminate this effect, and REM sleep enhances acquisition of new learning.
Empirical evidence suggests that the brain during perception and decision-making has access to both point estimates of any external stimulus and to the certainty about this estimate. This requires a neural representation of entire probability distributions in the brain. Two alternatives for neural codes supporting such representations are probabilistic population codes (PPC) and sampling-based representations (SBR). We examined the consequences of an SBR and its implications in the context of classical psychophysics. We derive analytical expressions for the implied psychophysical performance curves depending on the number of samples collected (i.e. the stimulus presentation time), which constitute the theoretical limit for optimal performance. This time-dependence allows us to contrast SBR with PPC, in which probability distributions are represented explicitly and near-instantaneously as opposed to successively over time as for sampling. We compared our predictions with empirical data for a simple two-alternative-choice task distinguishing between a horizontal and a vertical Gabor pattern embedded in Gaussian noise. Recasting the decision-making process in the sampling framework also allows us to propose a new computational theory for endogenous covert attention. We suggest that the brain actively reshapes its representation of the posterior belief about the outside world in order to collect more samples in parts of the stimulus space that is of greatest behavioral relevance (i.e. entails rewards or costs). We show that compared to using the veridical posterior, the benefit of such a mechanism is greatest under time pressure – exactly when the largest effects due to endogenous attention have traditionally been seen. We present experimental data for a task in which attention has been manipulated by varying the behavioral relevance of two stimuli concurrently on the screen, but not their probabilities as traditionally done.
Recently, several studies proposed a probabilistic framework for explaining the phenomenon of binocular rivalry, as an alternative to the classic bottom-up or eye-dominant interpretation of it. According to this framework, perception is generated from the observer’s internal model of the visual world, based on sampling-based probabilistic representations and computations in the cortex. To test the validity of this proposal, we trained participants with repeated four patterns of two-Gabor patches corresponding to the four possible perceptions in binocular rivalry settings, with a particular probability distribution of appearance (10%, 40%, 15% and 35%). We also tested participants’ prior and posterior distributions of these four perceptions in both binocular rivalry and non-rivalry situations, where they either made judgments by what was perceived in rivalry or guessed what could possibly be the answers of Gabor orientation pairs when they saw only non-rivalry Gaussian noise. Kullback–Leibler divergence and resampling methods were used to compare the pretest and posttest distributions from each individual participant. For the non-rivalry inference, three out of four participants showed significant difference (ps<0.05) between pre and post distributions of the four possible answers. Compared with the pretest, the post-test distribution shifted towards the target distribution manipulated in the training session. In contrast, for binocular rivalry, none of the participants showed change in the distributions of four perceptions overall from pretest to posttest, suggesting no learning effect transferred from non-rivalry training. Further analysis on the relationship between perception duration time and distribution changes in rivalry showed that with longer perception duration it was more likely to find pre-test and post-test distribution differences. However, the transition from pretest to posttest did not necessarily follow the target distribution from training. These results provided no decisive evidence that binocular rivalry is a visual process based on probabilistic representation.
Growing behavioral evidence suggests that animals and humans represent uncertainty about both high and low-level sensory stimuli in the brain for probabilistic inference and learning. One proposal about the nature of the neural basis of this representation of uncertainty suggests that instantaneous membrane potentials of cortical sensory neurons correspond to statistical samples from a probability distribution over possible features those neurons represent. In this framework, the quality of the representation critically depends on the number of samples drawn, and hence on the time available to perform a task. This implies a strong link between the available time and the reliability of the representation. We tested this hypothesis in an orientation matching experiment with two distinct types of stimuli: circles consisting of 1-4 Voronoi patches, each filled in with a number of gray-scale Gabor wavelets with their orientations sampled from a Gaussian distribution with a different mean orientation; and 2-10 differently oriented line segments spaced evenly on a circle. After 2 seconds of stimulus presentation subjects were asked to match the orientation of one of the patches or lines in the stimulus, and indicate their certainty about the correctness of the orientation match. To test our predictions, we manipulated the number of samples on a trial-to-trial basis by varying the time available to respond. Without time constraints, subjects’ performance and certainty judgment were significantly correlated independent of the number of patches or lines the stimuli consisted of. With a decrease in available time, subjects’ orientation and certainty judgments followed the theoretically predicted trends. Importantly, a decrease in response time lead to a decrease in correlation between performance and uncertainty, even though the performance remained unchanged. Therefore, limiting the response time, and consequently the number of samples drawn, significantly influences the quality of uncertainty representation in accord with the sampling hypothesis.
Learning abstract rules in the auditory and visual domains is customarily investigated with the AAB vs. ABB paradigm where each scene contains three auditory events or visual objects and either identity or an attribute of these items, such as the size of the objects, follows a same-same-different (i.e. AAB) pattern during a training period. In a subsequent test session, never seen before items are used and subjects’ preference to judge the AAB over ABB arrangements as familiar is taken as evidence for acquiring the abstract rule. We asked whether 2D retinal or 3D perceptual size is the basis of this judgment in case of visual rule learning of size arrangements. We used three triplets of 3D computer graphic colored objects arranged in perspective so that by physical extent on the screen they followed a large-large-small (AAb) template, but due to perspective their perceptual appearance was (aBB). After 2 minutes of random sequential presentation of the triplets for 2 sec each without any explicit task, two tests were administered with two versions of instruction. In the first test (No Context), context and perspective were taken away, and triplets were presented horizontally on white background, in the second (Context), exactly the same context was used as during the practice. The instructions were either choose the more familiar scene (Naïve) or considering size, chose the more familiar scene (Cued). In the Naïve-No Context condition, subject showed no preference between AAb and aBB, which changed in the Cued condition to significant aBB preference. In the Cued-Context condition, subjects showed a strong aBB preference. However, in the Naïve-Context condition, they switched to significant AAb preference. Thus size-rule coding seems to utilize high-level perceptual coding of size when directed explicitly, but in implicit familiarity tasks the more veridical retinal coding has a stronger influence.
Linking eye-movement to visual perception or to learning has been notoriously difficult due to the fact that the visual stimulus is either too simplified providing no insights to the true nature of learning or with too rich input, the process of learning becomes intractable. Visual statistical learning (VSL) provides an ideal framework for such studies since it uses stimuli with precisely controlled statistics and regular spatial layout. We used the classical VSL paradigm combined with eye tracking and asked whether this controlled implicit learning paradigm allows following the contribution and development of eye movements during the learning process. Stimuli were based on 12 simple shapes combined into six base-pairs. From this alphabet, each scene was composed by randomly selecting three of the base-pairs and juxtaposing them on a grid to generate over 140 scenes that were shown sequentially for 3 sec each on a large 4*3 feet screen while the subjects’ eye movements were monitored. Subjects had no task beyond attentively observing the scenes. Post practice, subjects were given a test with multiple trials, where they had to choose between true building base-pairs and random combination of pairs based on their judgment of familiarity. Subjects typically became familiar with the base-pairs to a different degree, showing a wide variation of success in choosing the true base-pair over a foil. This distribution of percent correct values was correlated with various measures of eye-movement. We found a correlation between the amount of eye-fixations and the total fixation time on the shapes of the highly learned pairs versus the pairs that weren’t learned. These results provide a first indication that not only in highly explicit cognitive tasks, but even in implicit observational tasks, eye movements have a tight link to the acquired knowledge of the visual scenes.
Implicit skill learning underlies not only motor, but also cognitive and social skills. Nevertheless, the ontogenetic changes in humansʼ implicit learning abilities have not yet been comprehensively characterized. We investigated such learning across the life span, between 4-85 years of age with an implicit probabilistic sequence learning task, and we found that the difference in implicitly learning strongly vs. weakly predictable events exhibited a characteristic and rapid decrement around age of 12. These lifelong learning efficiency measurements support an extension of the traditional 2-stage lifespan skill acquisition model: in addition to a decline above the age 60 reported in previous studies, sensitivity to raw probabilities and, therefore, acquiring fundamentally new skills is significantly more effective until early adolescence than later in life. These results suggest that due to developmental changes in early adolescence, implicit skill learning processes undergo a marked shift in weighting raw probabilities vs. more complex interpretations of events, which, with appropriate timing, prove to be an optimal strategy for human skill learning.
Brandeis University University of Rochester Brandeis University, USA Human infants are known to implicitly learn statistical regularities of their sensory environment in various perceptual domains. Visual statistical leaning studies with adults have illustrated that this learning is highly sophisticated and well approximated by optimal probabilistic chunking of the unfamiliar hierarchical input into statistically stable segments that can be interpreted as meaningful perceptual units. However, the emergence and use of such perceptual chunks at an early age and their relation to stimulus complexity have not been investigated. In three experiments, we found that 9-month-old infants can extract and encode statistical relationships within complex, hierarchically structured visual scenes, but they are not able to identify and handle these chunks as individual structures in the same manner as adults. These results suggest that as stimulus complexity increases, infantsʼ ability to extract chunks becomes limited, even though they are perfectly able to encode the structure of the scene. Apparently, the ability to use embedded features in more general and complex contexts emerges developmentally after encoding itself is operational.
According to the sampling hypothesis, the activity of sensory cortex can be interpreted as drawing samples from the probability distribution over features that it implicitly represents. Perceptual inference is performed by assuming that the samples are drawn from an internal model that the brain has built of the external world (Fiser et al 2010). We explore the implications of this hypothesis in the context of a perceptual decision-making task and present three findings: (1) Because the simple generative model for typical experimental stimuli does not match the rich internal model of the brain, the psychophysical performance is below what is theoretically possible based on the sensory neurons’ responses. This can explain why previous studies have found that surprisingly few sensory neurons are required to match the performance of the animal, and why traditional decoding models need to invoke ad-hoc “decision noise” (Shadlen et al 1996) when pooling the responses of all relevant sensory neurons. (2) We show that in the sampling framework typical 2AFC tasks induce higher correlations between neuron pairs supporting the same choice, than between those contributing to different choices – as has previously been observed empirically (Cohen & Newsome 2008). (3) We demonstrate that, given the limited number of samples in a trial and a reward structure that is strongly concentrated on particular parts of the sampling space, expected reward is maximized by sampling from a probability distribution other than the veridical posterior (for a related, but parametric, idea see Lacoste-Julien et al 2011). Based on these findings we propose that the brain actively adapts the posterior distribution to account for (1) and (3), and that this adaptation is closely related to the cognitive concept of attention. Using this interpretation of attention, we replicate existing neurophysiological findings and make new predictions.
Traditional assessments of the development of the visual system typically use change in selectivity to particular features such as orientation or direction to determine the maturity of visual cortical circuits. Directional selectivity tuning (DS) was shown not only to increase rapidly and significantly in the two weeks after eye opening but also to exhibit clear experience-dependent maturation (Li et al. 2008, Nature). However, the usefulness of this measurement depends on the assumption that selectivity to a feature such as direction is a direct and precise indicator of how well suited the visual system is for normal functioning. We have developed an alternative measurement based on the statistical similarity of spontaneous and visually evoked activity patterns in the visual cortex as measured by Kullback-Leibler divergence (KL). This measure assesses the optimality of information encoding given the statistics of the visual input, and under the assumption that the visual system encodes information probabilistically (Berkes et al. Science 2011). We showed previously that information encoding becomes more optimal with age; however, it remains unclear whether this change is driven by visual experience or purely developmental factors. In the present work, we explore the relationship between traditional selectivity measurements and our measurement of development in animals at the same stage of development, but with varying exposure to visual experience. We recorded extracellularly in V1 of ferrets at P30 using implanted line arrays of microwire electrodes. At this age, ferrets’ eyes are closed limiting their visual experience prior to the experiment. First we conducted a pretest to obtain measurements of neural activity in the awake animal in response to drifting gratings, natural movies, as well as spontaneous activity. This enabled us to obtain measurements of both DS and the KL between the activity patterns during presentation of different types of stimuli in the same animal and at the same stage of visual development. Next, animals underwent 10-15 hours of training consisting of passively viewing full-field gratings drifting in different directions under isoflurane anesthesia. After training, we conducted a posttest containing the same stimulus conditions as pretest thus allowing us to directly assess the role of visual experience in development as measured by both DS and KL divergence between distributions of neural activity patterns under different stimulus conditions. Furthermore, this allowed us to elucidate the relationship between the two measures and the differences in their trends across different exposures to visual experience.
2011
Recent findings suggest that humans represent uncertainty for statistically optimal decision making and learning. However, it is unknown whether such representations of uncertainty extend to multiple low-level elements of visual stimuli, although this would be crucial for optimal probabilistic representations. We examined how subjects’ subjective assessment of uncertainty about the orientations of multiple elements in a visual scene and their performance in a perceptual task are related. Stimuli consisted of 1–4 Voronoi patches within a circular 2º wide area, each patch filled with gray-scale Gabor wavelets drawn from distributions with different mean orientations. After a 2 s presentation, the stimulus disappeared and the subjects had to select the overall orientation around a randomly specified location within the area of the stimulus, and report their confidence in their choice. We found that subjects’ performance, as measured by the accuracy of the selected orientation, and their uncertainty judgment were strongly correlated (p<0.00001) even if multiple different orientations were present in the stimulus, and independently of the number of patches. These results suggest that humans not only represent low-level orientation uncertainty, but that this representation goes beyond capturing a general mean and variance of the entire scene.
Although a number of recent behavioral studies implied that the brain maintains probabilistic internal models of the environment for perception, motor control, and higher order cognition, the neural correlates of such models has not been characterized so far. To address this issue, we introduce a new framework with two key ingredients: the “sampling hypothesis” and spontaneous activity as a computational factor. The sampling hypothesis proposes that the cortex represent and compute with probability distributions through sampling from these distributions and neural activity reflect these samples. The second part of the proposal posits that spontaneous activity represents the prior knowledge of the cortex based on internal representations about the outside world and internal states. First, I describe the reasoning behind the proposals, the evidence supporting them, and will derive a number of empirically testable predictions based on the framework. Next, I provide some new results that confirm these predictions in both the visual and the auditory cortices. Finally, I show how this framework can handle previously reported observations about trial-to-trial variability and contrast-independent coding. These results provide a general functional interpretation of the surprisingly high spontaneous activity in the sensory cortex.
Human infants are known to learn statistical regularities of the sensory environment implicitly in various perceptual domains. Visual statistical leaning studies have illustrated that this learning is highly sophisticated and well_approximated by optimal probabilistic chunking of the unfamiliar input. However, the emergence and unitization of such perceptual chunks at an early age and their relation to stimulus complexity have not been investigated before. This study examines how 8_month_old infants can extract statistical relationships within more complex, hierarchically structured visual scenes and how unitization of chunks is linked to familiarity performance. In the first experiment, infants were habituated to quadruplet scenes composed of a triplet of elements always appearing in the same relative spatial arrangement and one noise element connected to the triplet in various ways. After meeting a criterion of habituation, in each of several test trials, infants saw one original triplet and a new triplet containing a rearrangement of familiar elements. Contrary to earlier results obtained with pairs rather than triplets, infants did not show a significant preference for either test stimulus (N = 20, p > 0.9). In a second experiment, infants were habituated using the same quadruplet scenes, but during the test, they saw one of the habituation quadruplets, and a second quadruplet in which the associated noise element was switched with a noise element from another triplet. Infants that habituated (N = 13) to the familiar quadruplet looked longer to the novel quadruplets, indicating they can recognize a change of one single element (p = 0.026), whereas non_habituating infants (N = 9) showed no preference (p > 0.9). These results suggest that as stimulus complexity increases, infants’ ability to learn and unitize chunks becomes limited, even though they are perfectly able to encode the structure of the scene. Apparently, unitization and the ability to use embedded features in more general contexts emerge after encoding itself is already operational.
There is increasing behavioral evidence that humans represent uncertainty about sensory stimuli in a way that it is suitable for decision making and learning in a statistically optimal manner. Do such representations of uncertainty exist for low-level visual stimuli, and furthermore, are they probabilistic in nature? We tested whether subjective assessment of the orientation uncertainty of a stimulus consisting of a fixed number of Gabor wavelets of different orientations reflects the true distribution of orientation uncertainty of the stimulus. Textured gray-scale stimuli were created by superimposing Gabor wavelets of three spatial frequency bands with their orientation randomly sampled from a bimodal Gaussian distribution. After 2 seconds of stimulus presentation, two oriented lines were displayed and subjects were asked to indicate the overall orientation of the stimulus by choosing one of the lines, or to opt not to respond if they were uncertain about the orientation. The orientation of the two lines matched the mean orientation of the stimulus orientation distribution and one of the modes. On average, subjects strongly preferred the mode (65%) over the mean (20%) and only rarely chose not to respond (15%) when the distribution of the orientations had two prominent modes. Increasing the variance of each mode led to a gradual reversal of ratios between the “mode” and “uncertain” responses. When the increase of variances changed the shape of the distribution to unimodal, subjects chose the mode 25%, the mean 15%, and the “uncertain” option 60% of the time. Results suggest that uncertainty associated with low level visual stimuli is explicitly represented as a probability distribution at a level of precision that goes beyond that of a simple parametric representation.
A number of recent psychophysical studies have argued that human behavioral processing of sensory inputs is best captured by probabilistic computations. Due to conflicting cues, real scenes are ambiguous and support multiple hypotheses of scene interpretation, which require handling uncertainty. The effects of this inherent perceptual uncertainty have been well-characterized on immediate perceptual decisions, but the effects on learning (beyond non-specific slowing down) have not been studied. Although it is known that statistically optimal learning requires combining evidence from all alternative hypotheses weighted by their respective certainties, it is still an open question whether humans learn this way. In this study, we tested whether human observers can learn about and make inferences in situations where multiple interpretations compete for each stimulus. We used an unsupervised visual learning paradigm, in which ecologically relevant but conflicting cues gave rise to alternative hypotheses as to how unknown complex multi-shape visual scenes should be segmented. The strength of conflicting segmentation cues, “high-level” statistically learned chunks and “low-level” grouping features of the input based on connectedness, were systematically manipulated in a series of experiments, and human performance was compared to Bayesian model averaging. We found that humans weighted and combined alternative hypotheses of scene description according to their reliability, demonstrating an optimal treatment of uncertainty in learning. These results capture not only the way adults learn to segment new visual scenes, but also the qualitative shift in learning performance from 8-month-old infants to adults. Our results suggest that perceptual learning models based on point estimates, which instead of model averaging evaluate a single hypothesis with the “best explanatory power” only, are not sufficient for characterizing human visual learning of complex sensory inputs.
Classical studies of face perception have used stimulus sets with standardized pose, feature locations and extremely impoverished information content. It is unclear how the results of these studies translate to natural perception, where faces are typically encountered in a wide variety of viewpoints and conditions. To address this issue, we used a 2-AFC coherence paradigm, a novel method of image generation and photographs of real faces presented at multiple viewpoints in natural context. A library of portraits, with 10–15 images of each person in various positions, was collected and in each image the prominent features (eye, mouth, ear, etc.) were labeled. Images were decomposed using a bank of Gaussian-derivative filters that gave the local orientation, contrast and spatial frequency, then reconstructed using a subset of these elements. Noise was added by altering the proportion of filter elements in their correct, signal location or a random noise location. On each trial, subjects first viewed a noiseless image, followed by noisy versions of a different exemplar of the same face and of a different face, and had to identify which image matched the person in the source image. The proportion of elements in the correct location on each trial was varied using a staircase procedure to maintain 78% correct responses. Each labeled feature was then analyzed independently by reverse correlation based on correct and incorrect trials. For correct identification, a significantly higher proportion of signal elements were necessary in the hair, forehead and nose regions, whereas elements in regions indicated as diagnostic in classical studies based on standardized stimulus sets, such as eye and mouth, were significantly less influential. These results are in odds with earlier findings and suggest that under natural conditions humans use a more extended and different set of features for correct face identification.
There is growing evidence that humans and animals represent the uncertainty associated with sensory stimuli and utilize this uncertainty during planning and decision making in a statistically optimal way. Recently, a nonparametric framework for representing probabilistic information has been proposed whereby neural activity encodes samples from the distribution over external variables. Although such sample-based probabilistic representations have strong empirical and theoretical support, two major issues need to be clarified before they can be considered as viable candidate theories of cortical computation. First, in a fluctuating natural environment, can neural dynamics provide sufficient samples to accurately estimate a stimulus? Second, can such a code support accurate learning over biologically plausible time-scales? Although it is well known that sampling is statistically optimal if the number of samples is unlimited, biological constraints mean that estimation and learning in cortex must be supported by a relatively small number of possibly dependent samples. We explored these issues in a cue combination task by comparing a neural circuit that employed a sampling-based representation to an optimal estimator. For static stimuli, we found that a single sample is sufficient to obtain an estimator with less than twice the optimal variance, and that performance improves with the inverse square root of the number of samples. For dynamic stimuli, with linear-Gaussian evolution, we found that the efficiency of the estimation improves significantly as temporal information stabilizes the estimate, and because sampling does not require a burn-in phase. Finally, we found that using a single sample, the dynamic model can accurately learn the parameters of the input neural populations up to a general scaling factor, which disappears for modest sample size. These results suggest that sample-based representations can support estimation and learning using a relatively small number of samples and are therefore highly feasible alternatives for performing probabilistic cortical computations.
Recent psychophysical experiments imply that the brain employs a neural representation of the uncertainty in sensory stimuli and that probabilistic computations are supported by the cortex. Several candidate neural codes for uncertainty have been posited including Probabilistic Population Codes (PPCs). PPCs support various versions of probabilistic inference and marginalisation in a neurally plausible manner. However, in order to establish whether PPCs can be of general use, three important limitations must be addressed. First, it is critical that PPCs support learning. For example, during cue combination, subjects are able to learn the uncertainties associated with the sensory cues as well as the prior distribution over the stimulus. However, previous modelling work with PPCs requires these parameters to be carefully set by hand. Second, PPCs must be able to support inference in non-linear models. Previous work has focused on linear models and it is not clear whether non-linear models can be implemented in a neurally plausible manner. Third, PPCs must be shown to scale to high-dimensional problems with many variables. This contribution addresses these three limitations of PPCs by establishing a connection with variational Expectation Maximisation (vEM). In particular, we show that the usual PPC update for cue combination can be interpreted as the E-Step of a vEM algorithm. The corresponding M-Step then automatically provides a method for learning the parameters of the model by adapting the connection strengths in the PPC network in an unsupervised manner. Using a version of sparse coding as an example, we show that the vEM interpretation of PPC can be extended to non-linear and multi-dimensional models and we show how the approach scales with the dimensionality of the problem. Our results provide a rigorous assessment of the ability of PPCs to capture the probabilistic computations performed in the cortex.
High-throughput neuroscience presents unique challenges for exploratory data analysis. Clustering often helps experimenters make sense of data, but model-based clustering techniques, including Dirichlet-process mixture models, have difficulty when differing subsets of dimensions are best explained by differing clusterings. As a result, they can be misled by irrelevant dimensions, they easily miss structure that dimensionality reduction methods find, and they often predict less accurately than discriminative alternatives. We introduce cross-categorization, a modeling technique for heterogeneous, high-dimensional tabular data that addresses these limitations. Based on an efficient MCMC inference scheme for a novel nonparametric Bayesian model, cross-categorization infers which groups of dimensions share a common generative history and are therefore mutually predictive.
2010
Sparse coding is a powerful idea in computational neuroscience referring to the general principle that the cortex exploits the benefits of representing every stimulus by a small subset of neurons. Advantages of sparse coding include reduced dependencies, improved detection of co-activation of neurons, and a more efficient encoding of visual information. Computational models based on this principle have reproduced the main characteristics of simple cell receptive fields in the primary visual cortex (V1) when applied to natural images. However, direct tests on neural data of whether sparse coding is an optimization principle actively implemented in the brain have been inconclusive so far. Although a number of electrophysiological studies have reported high levels of sparseness in V1, these measurements were made in absolute terms and thus it is an open question whether the observed high sparseness indicates optimality or simply high stimulus selectivity. Moreover, most of the recordings have been performed in anesthetized animals, but it is not clear how these results generalize to the cell responses in the awake condition. To address this issue, we have focused on relative changes in sparseness. We analyzed neural data from ferret and rat V1 to verify two basic predictions of sparse coding: 1) Over learning, neural responses should become increasingly sparse, as the visual system adapts to the statistics of the environment. 2) An optimal sparse representation requires active competition between neurons that is realized by recurrent connections. Thus, as animals go from awake state to deep anesthesia, which is known to eliminate recurrent and top-down inputs, neural responses should become less sparse, since the neural interactions that support active sparsification of responses are disrupted. To test the first prediction empirically, we measured the sparseness of neural responses in awake ferret V1 to natural movies at various stages of development, from eye opening to adulthood. Contrary to the prediction of sparse coding, we found that the neural code does adapt to represent natural stimuli over development, but sparseness steadily decreases with age. In addition, we observed a general increase in dependencies among neural responses. We addressed the second prediction by analyzing neural responses to natural movies in rats that were either awake or under different levels of anesthesia ranging from light to very deep. Again, contrary to the prediction, sparseness of cortical cells increased with increasing levels of anesthesia. We controlled for reduced responsiveness of the direct feedforward connections under anesthesia, by using appropriate sparseness measures and by quantifying the signal- to-noise ratio across levels of anesthesia, which did not change significantly. These findings suggest that the representation in V1 is not actively optimized to maximize the sparseness of neural responses. A viable alternative is that the concept of efficient coding is implemented in the form of optimal statistical learning of parameters in an internal model of the environment.
Forebrain taste information processing is accomplished mainly by three reciprocally connected forebrain regions -primary gustatory cortex (GC), (basolateral) amygdala (AM), and orbitofrontal cortex (OFC)- loosely characterized as the neural sources of sensory, palatability-related, and cognitive information, respectively. It has been proposed that the perception of complex taste stimuli involves an intricate flow of information between these regions in real time. However, empirical confirmation of this hypothesis and a detailed analysis of the multidirectional flow of information during taste perception have not yet been presented before. We have simultaneously recorded local field potentials from GC, AM, and OFC in awake behaving rats under two conditions as controlled aliquots of either preferred or not preferred taste stimuli were placed directly on their tongues via intra-oral cannulae. Half of the deliveries were active, as the rat pressed a bar to receive the taste upon receiving an auditory ‘go’ signal, the other half of deliveries were passive when the rat received a tastant at random times. Peri-delivery signals from the three areas were analyzed by computing transfer entropy, a method that measures directional information transfer between coupled dynamic systems by assessing the reduction of uncertainty in predicting the current state of the systems based on their previous states. The results of this analysis reveal the complexity and context specificity of perceptual neural taste processing. Passive taste deliveries caused an immediate and strong flow of information that ascended from GC to both AM and OFC (p<0.001). However, within the 1.5-2.0 sec in which our rats typically identified and acted on (swallowing or expelling) the tastes, feedback from AM to GC became a prominent feature of the field potential activity (p<0.001). This finding confirms and extends earlier single cell results showing that palatability-related information appears in AM single- neuron responses soon after taste delivery, and that there is a sudden shift in the content of both GC and AM single-neuron responses at ~1.0 sec following delivery, as palatability-related information appears in GC and subsides in AM. The neural response to active taste deliveries differed from that to passive deliveries in important ways. The massive immediate GC to AM/OFC flow was greatly decreased and delayed. Instead, there was an increased and lasting information flow from OFC to GC (p<0.01) immediately after the tone. The likely reason for this reduction was obvious: tone onset led to an anticipation of taste delivery that activated a descending flow of information from the cognitive centers in OFC to the primary sensory cortex, which greatly changed the actual neural processing of the stimulus itself in GC. These results place earlier single-neuron findings into a functional dynamic framework, and offer an explanation of how the parts of the sensory system work together to give rise to complex perception. They suggest that perception is not a simple bottom-up process in which a stimulus is coded by progressively higher centers of the brain, rather various bottom-up and top-down effects jointly define and greatly alter stimulus processing as early as in the primary sensory areas. In agreement with our predictions, we found that the distribution of speech- evoked activity is consistently more similar to spontaneous activity than the distribution of noise-evoked activity, for both the instantaneous distribution of activity and for transition probability. These results provide new evidence for stimulus specific adaptation in the cortex that leads to preference for natural stimuli, and also provide additional support for the sampling hypothesis. Our findings in A1 complement our earlier data from V1, suggesting that the match between spontaneous and evoked activity might be a universal hallmark of representation and computation in sensory cortex.
In the past years, there has been a paradigm shift in the field of cognitive neuroscience as a number of behavioral studies demonstrated that animals and humans can take into account statistical uncertainties of task, reward, and their own behavior, in order to achieve optimal task performance. These results have been interpreted in terms of statistical inference in probabilistic models. However, such an interpretation raises the question of how cortical networks represent and make use of the probability distributions necessary to carry out such computations. Recently, we have proposed that neural activity patterns correspond to samples from the posterior distribution over interpretations of the sensory input, a hypothesis that is consistent with several experimental observations (e.g. trial-to-trial variability). Last year, using this framework, we verified experimentally that the distribution of spontaneous activity in such probabilistic representations adapts over development to match that of evoked activity averaged over stimuli, based on recordings from V1 of awake ferrets. In the present study, we define and test two novel predictions of this framework. First, we predict that the match between evoked and spontaneous activity should be specific to the distribution of neural activity evoked by natural stimuli, and not to that evoked by artificial stimulus ensembles. We expect this match to hold for instantaneous neural activity, and for temporal transitions between activity pattern. Second, if this hypothesis captures the general computational strategy in the sensory cortex, it should be valid across sensory modalities. To test these predictions, we analyzed single unit data (N=32 over 6 recordings) recorded simultaneously from multiple electrodes in the primary auditory cortex (A1) of awake ferrets in three stimulus conditions: a natural condition consisting in a stream of continuous speech, a white noise (0-20 kHz) condition, and a spontaneous activity condition where the animal was listening in silence. Speech was chosen since its spectrotemporal characteristics are similar to those of natural sounds. We analyzed the neural data, which was discretized in 25 ms bins, binarized, and the distribution of instantaneous, joint activity, and the transition probability from one activity pattern to the next was estimated in the three conditions. We measured dissimilarity between the silence and stimulus condition distributions using Kullback-Leibler divergence. The robustness of our results was estimated using a bootstrapping technique.
Neural responses to identical sensory stimuli can be highly variable across trials, even in primary sensory areas of the cortex. This raises the question of how such areas reliably transmits sensory-evoked responses to guide appropriate behavior. Internally-generated, spontaneous activity, which is ubiquitous in the cortex, is a leading candidate for causing much of the observed response variability. Recent theoretical analyses suggested that chaotic spontaneous activity generated by a recurrent network model can be strongly suppressed by external input in a stimulus-dependent manner. A hallmark feature of this result is a non-monotonic temporal frequency – dependence, which implies that there is an optimal stimulus frequency for suppression of internally generated noise. To test the prediction that cortical areas operate similar to such models, we investigated spontaneous and visually-evoked extracellular neural activity from 57 mostly multi-units (MUs) in the primary visual cortex (V1) of 6 rats. We recorded from the rats under five conditions: while fully awake and while under 4 different levels of isoflurane anesthesia. The anesthetized conditions were included to investigate the responses of the neural circuitry as its dynamic behavior is gradually modified. Anesthesia ranged from very light to deep, and stable levels were verified by various physiological parameters such as breathing rate, reflex response, and local field potential structure. Rats were head-fixed in a sound- and light- attenuating box while passively viewing flashing stimuli on a monitor 6 inches away from the retina. Five different stimulus conditions were used for all rats in all states. Full-field flashing visual stimuli were presented at four frequencies, ranging from 1 Hz to 7.5 Hz, and spontaneous neural activity was also recorded during periods of complete darkness. Stimulus appearance was interleaved and randomized. Variability was assessed by computing Fano-factors over a range of spike-counting intervals. We found that variability in spontaneous neural firing is actively and selectively suppressed by visual stimulation both in awake and anesthetized conditions. However, the pattern of suppression was different: in the awake case, it followed the theoretical prediction showing a significant dip in the Fano-factor across the different temporal frequencies of the stimuli. This frequency-dependency vanished with increased anesthesia. In addition, we found that the lowest level of noise and the largest amount of suppression compared to the spontaneous condition across all evoked conditions occurred in the awake state. Importantly, power spectrum analysis showed that this patterns of frequency-dependent noise suppression could not be explained by differences in intrinsic neural oscillations. These results suggest the existence of an active noise-suppression mechanism in the primary visual cortex of the awake animal that is tuned to operated maximally in the awake state for stimuli modulated at behaviorally relevant frequencies.
2009
The proposal that cortical activity in the visual cortex is optimized for sparse neural activity is one of the most established ideas in computational neuroscience. However, direct experimental evidence for optimal sparse coding remains inconclusive, mostly due to the lack of reference values on which to judge the measured sparseness. Here we analyze neural responses to natural movies in the primary visual cortex of ferrets at different stages of development and of rats while awake and under different levels of anesthesia. In contrast with prediction from a sparse coding model, our data shows that population and lifetime sparseness decrease with visual experience, and increase from the awake to anesthetized state. These results suggest that the representation in the primary visual cortex is not actively optimized to maximize sparseness.
The coding of information by neural populations depends critically on the statistical dependencies between neuronal responses. However, there is no simple model that can simultaneously account for (1) marginal distributions over single-neuron spike counts that are discrete and non-negative; and (2) joint distributions over the responses of multiple neurons that are often strongly dependent. Here, we show that both marginal and joint properties of neural responses can be captured using copula models. Copulas are joint distributions that allow random variables with arbitrary marginals to be combined while incorporating arbitrary dependencies be- tween them. Different copulas capture different kinds of dependencies, allowing for a richer and more detailed description of dependencies than traditional sum- mary statistics, such as correlation coefficients. We explore a variety of copula models for joint neural response distributions, and derive an efficient maximum likelihood procedure for estimating them. We apply these models to neuronal data collected in macaque pre-motor cortex, and quantify the improvement in cod- ing accuracy afforded by incorporating the dependency structure between pairs of neurons. We find that more than one third of neuron pairs shows dependency concentrated in the lower or upper tails for their firing rate distribution.
How do we infer from sensation the state of the external world? Humans and animals have been shown to perform statistically optimal inference and learning during perception in the presence of noise and uncertainty in the presented stimuli. This points to a probabilistic representation of the sensory input, where evidence coming from sensation is optimally combined with an internal model of the environment. Indeed, neural correlates of the uncertainty and probability of behaviorally relevant stimuli have been reported in brain areas related to decision- making. Moreover, manipulations of the statistics of the environment are known to be reflected in changes in the neural representation, which are compatible with some probabilistic accounts of learning. However, there has been so far no evidence of statistically optimal inference and learning at the neural level. We have investigated general consequences of probabilistic inference in the sensory system under the assumptions that neural activity reflects sampling from the internal, probabilistic model of the world. This assumption makes the strong prediction that the joint distribution of spontaneous activity and that of evoked activity averaged over stimuli have to be identical. We analyzed multielectrode data from awake ferrets at various stage of post- natal development. Neural activity was recorded during evoked and spontaneous activity. We found that the similarity between activity evoked by natural movie stimuli and spontaneous activity significantly increased with visual experience, until, at the end of visual development, the two distributions were not significantly distinguishable (P>0.95). This similarity was brought about by a match between the spatial and temporal correlational structure of the activity patterns, rather than merely by preserved firing rates across conditions. Moreover, the match was specific to activity evoked by natural stimuli, and not by noise by grating stimuli. These results suggest that neural variability samples from a probabilistic model of the environment that is gradually being tuned to natural scene statistics by sensory experience as the visual system develops. The interpretation of neural activity as samples provides a missing link between the computational and neural level, opening the way to a systematic exploration of functional principles of cortical organization.
Visual statistical learning has been established as a paradigm for testing implicit knowledge that accumulates gradually with experience. Typically, subjects are presented with a stream of scenes composed of simple shapes arranged according to co-occurrence rules. Subjects observe the scenes without a defined task, and during the test subjects’ familiarity with the building blocks of the scenes is measured. However, the test in this paradigm usually directly follows the practice, while long-term effects are usually considered to last for hours or days. In addition, while the learning is implicit, the underlying structure of scenes can be summarized by a few explicit rules, which when told to the subject, the task becomes trivial. It is not clear, however, whether the implicit learning leads to explicit knowledge of the rules, or if the two types of learning are unrelated. To address these issues, we ran a modified visual statistical learning study, where subjects were tested one hour after the practice session. In addition, we varied the length of practice from 144 to 216 to 288 scenes. At short length, subjects showed no learning (55%, p>.05), in strong contrast with earlier results (74.7%, p<0.0001) where the practice and test without intermission yielded strong implicit learning. As the length of practice increased to 216, implicit familiarity emerged (82%, p<0.004), whereas with 288 trials not only did performance improve further (85%, p<0.0004), but explicit knowledge of the rules was reported by a majority of the subjects. Thus, even though visual statistical learning contributes to immediate familiarity, it is also the basis of more prolonged representations in long term memory. Moreover, this type of learning gradually leads to the emergence of explicit knowledge of the rules observed in the scenes, thus questioning the idea that implicit statistical and explicit rule learning are two separate processes.
Objectives: In performing search tasks, the visual system encodes information across the visual field and deploys a saccade to place a visually interesting target upon the fovea. The process of saccadic eye movements, punctuated by periods of fixation, continues until the desired target has been located. Loss of peripheral vision restricts the available visual information with which to plan saccades, while loss of central vision restricts the ability to resolve the high spatial information of a target. We investigate visuomotor adaptations to visual field loss with gaze-contingent peripheral and central scotomas. Methods: Spatial distortions (peak frequency 2 cpd) were placed at random locations in 25deg square natural scenes, with transitions from distorted to undistorted regions smoothed by a Gaussian (sd = 2 deg). Gaze-contingent central or peripheral simulated Gaussian scotomas sd=1 2 or 4 deg were updated at the screen rate (75Hz) based on a 250Hz eyetracker. The observer’s task was to search the natural scene for the spatial distortion and to indicate its location using a mouse-controlled cursor. Results: As the diameter of central scotomas increased or the diameter of peripheral scotomas decreased, so followed an increase in mean search times and the mean number of saccades and fixations. Fixation duration, saccade size and saccade duration were relatively unchanged across conditions. Conclusions: Both central and peripheral visual field loss cause functional impairment in visual search. The deficit is largely attributed to an increase in the number of saccades and fixations, with little change in visuomotor dynamics. Subjects frequently made saccades into blind areas and did not modify fixation durations to compensate for reduced acuity or change in temporal integration, suggesting that adaptations to visual impairment are not automatic and may benefit from rehabilitation training.
While in previous studies, a number of abstract characteristics of visual statistical learning have been clarified under various 2-dimesional settings, little effort was directed to understand how real visual dimensions in 3-dimensonal scenes interact during such learning. In a series of experiments using realistic 3D shapes and the dimensions of color, texture, and motion, we tested the Less-Is-More principle of learning, namely the proposal that information in independent dimensions do not interact in a simple additive manner to help learning. Following the original statistical learning paradigm, twelve arbitrary 3D shapes were used to compose large 3’x3′ scenes, where shape pairs followed particular co-occurrence pattern and scenes were composed of random combinations of such pairs. Similarly to the results with abstract 2D shapes, subjects automatically and implicitly learned the underlying structure of the scenes. However, there were notable differences in learning depending on the features of the stimuli. Humans performed well above chance in the baseline experiment with colored and textured shapes (63% correct, p<0.001). When they received the same training but with colors only, using a single type of shape and no texture, performance dropped to chance (51%, ns.), showing that providing the same color label information without hooks was not useful. However, removing color and texture or color and shape improved performance (both 68%, p< 0.001) showing that reducing the richness of the representations is not always detrimental. Finally, adding characteristic motion pattern to each shape did not elevate performance (65%, p< 0.001) demonstrating that even the most effective type of visual information does not necessarily speed up learning. These results support the Less-Is-More idea that the most effective learning requires the maximum amount of information that the system can reliably process based on its capacity limit and internal representation, which is not equivalent to having the most possible information.
How does the visual system integrate local features to represent global object forms? Previously we quantified human orientation sensitivity in complex natural images and found that orientation is encoded only with limited precision defined by an internal threshold that is set by predictability of the stimulus (VSS 2007). Here we tested the generality of this finding by asking whether local orientation information is integrated differently when orientation noise was distributed across a scene, and in an object identification task for natural images that were reconstructed from a fixed number of Gabor wavelets. In the noise discrimination task, subjects viewed pairs of images where orientation noise was added to the elements of only one image, both images, or was distributed evenly between the two images, and were required to identify the noisier pair of images. Sensitivity to orientation noise with the addition of external noise produced a dipper function that did not change with the manner in which noise was distributed, suggesting that orientation information is integrated consistently irrespective of the distribution of orientation information across the scene. In the identification task, subjects identified an object from four categories, randomly selected from a total of 40 categories. The proportion of signal Gabors, whose orientation and position were taken from the object, and noise Gabors, whose positions were randomly assigned, was adjusted to find the form coherence threshold for 75% correct object identification. Signal elements consisted of pairs of adjacent Gabors whose orientation difference was low (contour-defining), high (corner-defining), or randomly selected. Thresholds for image identification were only slightly elevated compared with earlier discrimination results, and were equal for all types of signal elements used. These results suggest that orientation information is integrated by perceptual templates that depend on orientation predictability but not on the complexity level of the visual task.
We have recently proposed that representations of novel multi-element visual displays learned and stored in visual long-term memory encode the independent chunks of the underlying structure of the scenes (Orban et al. 2008 PNAS). Here we tested the hypothesis that this internal representation guides eye movement as subjects explore such displays in a memory task. We used scenes composed of two triplets of small black shapes randomly selected from an inventory of four triples and arbitrarily juxtaposed on a grid shown on a 3’x3′ screen. In the main part of the experiment, we showed 144 trials with two scenes for 2 sec each with 500 msec blank between them, where the two scenes were identical except for one shape that was missing form the second scene. Subjects had to select from two alternatives the missing shape, and their eye movements were recorded during the encoding phase while they were looking at the first scene. In the second part of the experiment, we established the subject’s confusion matrix between the shapes used in the experiment in the given configurations. We analyzed the amount of entropy reduction with each fixation in a given trial based on the individual elements of the display and based on the underlying chunk-structure, and correlated these entropies with the performance of the subject. We found that, on average, the difference between the entropy reduction between the first and last 10 trials was significantly increased and correlated with improved performance when entropy was calculated based on chunks, but no such reduction was detected when entropy calculation was based on individual shapes. These findings support the idea that subjects gradually learned about the underlying structure of the scenes and their eye movements were optimized to gain maximal information about the underlying structure with each new fixation.
Recent studies suggest that the coherent structures learned from multi-element visual scenes and represented in human memory can be best captured by Bayesian model comparison rather than by traditional iterative pair-wise associative learning. These two learning mechanisms are polar opposites in how their internal representation emerges. The Bayesian method favors the simplest model until additional evidence is gathered, which often means a global, approximate, low-pass description of the scene. In contrast, pair-wise associative learning, by necessity, first focuses on details defined by conjunctions of elementary features, and only later learns more extended global features. We conducted a visual statistical learning study to test explicitly the process by which humans develop their internal representation. Subjects were exposed to a family of scenes composed of unfamiliar shapes that formed pairs and triplets of elements according to a fixed underlying spatial structure. The scenes were composed hierarchically so that the true underlying pairs and triplets appeared in various arrangements that probabilistically, and falsely, gave rise to more global quadruple structures. Subjects were tested for both true vs. random pairs and false vs. random quadruples at two different points during learning — after 32 practice trials (short) and after 64 trials (long). After short training, subjects were at chance with pairs (51%, p>0.47) but incorrectly recognized the false quadruples (60%, p<0.05). Showing a classic double dissociation after long training, subjects recognized the true pairs (59%, p<0.05) and were at chance with the quadruples (53%, p>0.6). These results are predicted well by a Bayesian model and impossible to capture with an associative learning scheme. Our findings support the idea that humans learn new visual representations by probabilistic inference instead of pair-wise associations, and provide a principled explanation of coarse-to-fine learning.
Neural responses in the visual cortex of awake animals are highly variable, display substantial spontaneous activity even when no visual stimuli are being processed, and the variability in both evoked activity (EA) and spontaneous activity (SA) is strongly structured. However, most theories of visual cortical function remain mute about the possible computational roles and consequences of such variability and treat it as mere nuisance or, at best, as an epiphenomenon. Here, we propose that neural response variability in EA and SA may be a hallmark of statistical inference carried out by the visual cortex and test a key prediction of this normative theory in multiunit recordings from awake ferrets. Under our working hypothesis, neural response variability represents uncertainty about stimuli: we treat cortical activity patterns as samples from an internal, probabilistic model of the environment. Thus, given a stimulus, EA can be interpreted as representing samples from the posterior probability distribution of possible causes underlying visual input. In the absence of a stimulus, this probability distribution reduces to the prior expectations assumed by the internal model as reflected by SA. This interpretation of EA and SA directly leads to a critical prediction about their relation: if they represent samples from the same, statistically optimal model of the environment, then the distribution of spontaneous activity must be identical to that of evoked activity averaged over natural stimuli. In practice, a perfect identity may not be achieved, but crucially, the two sides of this equation should become closer as the internal model of the environment implemented by the cortex is being matched to the statistics of natural scenes. We analyzed multiunit data from 14 awake P29-151 ferrets recorded with a linear array of 16 electrodes. Neural activity was recorded in two conditions: while the animal was watching a movie (EA), and while the animal was in complete darkness (SA). Neural data was discretized in 2ms bins and binarized. We constructed the joint distribution over possible states of the 16 channels in the two conditions, PEA and PSA, and computed the Kullback-Leibler (KL) divergence, a standard measure of statistical dissimilarity between these two distributions. We found that after visual development the distribution of EA was very close to that of SA (less than 1.5% of the minimum coding cost), that this similarity significantly increased with visual experience, and that it was brought about by a match between the spatial correlational structure of the activity patterns, rather than merely by preserved firing rates across conditions. A similarly significant increase in the match between the temporal correlational structure of EA and SA was also found. In addition, we found that classical theories of visual cortical function based on independence and sparseness were not supported by our data. These results suggest that neural variability samples from a probabilistic model of the environment that is gradually being tuned to natural scene statistics by sensory experience as the visual system develops.
2008
Human infants have been shown to implicitly learn rules, such as the repetition of ABB or ABA patterns, regardless of the identity of the participating items, both with sequential information during language development and with simultaneously presented visual patterns. However, in these studies the ABB or ABA patterns were defined by the identity of the items themselves. This leaves open the question of how successful humans are in extracting such rules in more complex situations when the rule is defined by a particular feature dimension of the items rather than by their identity. We examined the performance of adults presented with an implicit rule-learning task where both the color and the size of the items followed some underlying rules. Subjects were first exposed to a series of three different shapes presented simultaneously: five triplet scenes were viewed ten times each in random order during the learning phase. Patterns within each triplet varied in both size and color saturation following two different rules (AAB vs. ABA). The test phase consisted of triplets made of new elements not seen in the learning phase, which varied in size but had identical color saturation. In each trial, subjects saw two triplets, an AAB and an ABA pattern, and judged which triplet seemed more familiar. Surprisingly, adult subjects did not find the pattern of sizes shown during practice more familiar than the alternative, with a size difference of either 100 or 150 percent. These results suggest that successful visual rule-learning requires a much higher saliency of the rule in the given feature dimension than is expected based on the discrimination results.
Classical studies of the capacity of working memory have posited a fix limit for the maximum number of items human can store temporarily in their memory, such as 7-2 or 4-1. More recent results showed that when the stored items are viewed as complex multi-dimensional objects capacity can be increased and conversely, when distinctiveness of these items is minimized capacity is reduced. These results suggest a strong link between working memory and the nature of the representation of information based on the observer’s long-term memory. To test this conjecture, we formalized the information content of a set of stimulus by its description length, which relates the cost, the number of bits assigned to a particular stimulus, to its appearance likelihood given the representation the observer has. This formalism highlights that a high-complexity but familiar stimuli need less resource to encode and recall correctly than novel stimuli with lower complexity. Using this formalism, we developed a novel two-stage test to investigate the above conjecture. First, participants were trained in an unsupervised visual statistical learning task using multi-element scenes in which they are known to develop implicitly a chunked representation of the scenes. Next, they performed a change detection task using novel scenes that were composed from the same elements either with or without the chunk arrangements of the training session. Change detection results were significantly better with scenes that were composed of elements that retained the chunk arrangement. Thus the capacity of working memory determined by how easily the stimulus can be mapped onto the internal representation of the observer, and integrated object-based coding is a special case of this mapping.
The coding of information by neural populations depends critically on the statistical dependencies between neuronal responses. At the moment, however, we lack of a simple model that can simultaneously account for (1) marginal distributions over single-neuron spike counts that are typically close to Poisson; and (2) joint distributions over the responses of multiple neurons that are often strongly dependent. Here, we show that both marginal and joint properties of neural responses can be captured using Poisson copula models. Copulas are joint distributions that allow random variables with arbitrary marginals to be combined while incorporating arbitrary dependencies between them. Different copulas capture different kinds of dependencies, allowing for a riwcher and more detailed description of dependencies than traditional summary statistics, such as correlation coefficients. We explore a variety of Poisson copula models for joint neural response distributions, and derive an efficient maximum likelihood procedure for estimating them. We apply these models to neuronal data collected in the macaque pre-motor cortex, and quantify the improvement in coding accuracy afforded by incorporating the dependency structure between pairs of neurons.
Recently we proposed a computational framework in which we assumed that the visual cortex implicitly implements a generative model of the natural visual environment and performs its functions such as recognition and discrimination by inferring the underlying external causes of the visual input. In the present work, we test this framework by relating synthetic and measured neural data to the predictions of the underlying generative model. Two key elements of the proposal are that firing activity of individual neurons are samples form the underlying probability density function () that those cells represent, and that the spontaneous activity of the cortex represents the prior knowledge of the system about the external world. In order to test these ideas, a reliable method was developed to estimate the difference between the s of the spontaneous and visually evoked activities based on a limited number of samples. Our method exploits the full statistical structure of the data to estimate the Kullback-Leibler divergence between s of neural activities recorded under different conditions. First, we tested the method on synthetic data to demonstrate its feasibility, then we applied it to analyze neural recording from the primary visual cortex of awake behaving ferrets. Our results conforms the predictions of the generative framework and show how this framework can successfully describe the link between spontaneous and visually evoked activity and give a novel interpretation to the response variability of cortical responses.
A recently emerging computational framework of the visual cortex assumes that it implements a generative model of (natural) visual input. According to this view, the visual cortex implicitly embodies a statistical model of how external causes (the latent variables of the model) combine to form the visual input (the observed variables of the model). Given a visual stimulus, the cortex inverts the model (according to Bayes’ theorem), and thus infers which causes are likely to underlie it. Many psychophysical and physiological results are consistent with this hypothesis. However, testing this general idea directly is difficult, since it requires the correct specification not only of the generative model putatively implemented by the cortex, but also of its many implementational details. An alternative approach is to look for fundamental hallmarks of generative models in the cortex that are not specific to any particular model, but are characteristic of probabilistic inference and generation and that require only minimal assumptions about the implementational details. We argue that one such hallmark of any generative model which adequately represents its input is a direct relationship between the prior distribution of latent variables, X, and their posterior distribution given some data present in the observed variables Y: P(X) = integral( P(X|Y)P(Y) dY ) . Under the assumption that neural activity in the visual cortex represents samples from the distribution of latent variables, P(X) and P(X|Y) correspond to two different forms of V1 activity: that emerging in the absence of visual input (ie, spontaneous activity, SA), and that evoked by visual stimulus (EA), respectively. Thus, the above equation predicts that the statistics of SA must be identical to the statistics of EA (the latter integrated over a natural scene ensemble, P(Y)). Indeed, physiological recordings have shown that the statistics of EA movies in awake animals are remarkably similar to those recorded during SA. An other important consequence of this framework is that it provides a genuine explanation of the large trial-by-trial variability found in physiological recordings in awake animals. Based on this framework, we analyze the activity of a hierarchical belief network, as a prototypical generative model, in order to identify other statistical hallmarks of generative models that can be found in the visual cortex. We examine the effects of probabilistic phenomena such as the relation between evoked and spontaneous activity, explaining away and contextual effects, and the effect of presenting noisy or ambiguous stimuli to the model. We discuss the kind of statistics that could be collected in in-vivo recordings in order to verify these effects, including measures based on data from a limited number of neurons.
We investigated the structure of image features that support human object recognition using a novel 2-AFC form coherence paradigm. Grayscale images of everyday objects were analyzed with a multi-scale bank of Gabor-wavelet filters whose responses defined the positions, orientations and phases of Gabor patches that were used to reconstruct a facsimile of the original image. Signal Gabors were assigned the parameters of the original image, noise Gabors were assigned random positions, leaving the other parameters, and therefore the overall amplitude spectrum, unchanged. Observers were shown the reconstructed, 100% signal image and were then required to discriminate a target image containing a proportion of signal elements from one containing only noise elements. A staircase determined the proportion of signal elements that were required for correct identification on 75% of trials. We used the statistics of the original image to determine which elements were designated signal and which were designated noise in seven conditions. Signal elements were selected at random or from areas where local orientation variability, density or luminance contrast was either high or low in the original scene. Thresholds were the same for random, orientation variability and density conditions, but were significantly lower for the high contrast and significantly higher for the low contrast conditions. Importantly, the latter result held whether the contrast of the Gabors in the reconstructed scene were either fixed at all the same value or followed the contrast of the original scene. This means that recognition performance is determined by the feature structure of the original scene that has high contrast and not the high contrast elements of the experimental image. These results show that, in general, image identification depends on specific relationships among local features that define natural scenes and not basic statistical measures such as feature density, variability or the contrast values of individual features.
We examine how local position information of different complex scenes is represented in the visual system. A 2AFC paradigm was used to examine internal noise and sampling efficiency for three classes of stimuli: natural objects, fractal patterns and random circular patterns, all synthesized from the same set of Gabor wavelets. Each trial, a noiseless source image was presented first for 1 sec, followed by a reference image that contained a fixed amount of external position noise (s) on each element, and a target image containing additional position noise (s+Ds) under the control of a staircase. Subjects identified the image with less noise. Equivalent noise functions fitting the results indicated approximately identical internal noise but sampling efficiency that increased with predictability across image classes. This suggests a flexible position representation that compares the observed structure with prior experience.
Classical views of information flow in primary visual cortex suggest that orientation information is encoded early in a feedforward architecture and passed to higher levels of cortex for further processing. More recent studies suggest that top-down information can modulate processing of even basic visual attributes. We investigated whether responses in primary visual cortex are modulated by top-down effects evoked by differential rewarding of oriented grating stimuli. Multiunit extracellular recordings were obtained using a microwire electrode array chronically implanted in rat primary visual cortex while grating stimuli were presented under different reward conditions. An awake headfixed animal viewed alternating +45° and -45° sinusoidal grating stimuli. During a control sessions, gratings were passively presented with no reward. In three subsequent sessions, one grating (CS+) was paired with a water reward while the other grating (CS-) remained unrewarded. On the third rewarded session, units showed a two-fold increase in firing that plateaued and then returned to baseline during the CS+, while firing rates for the CS- remained relatively constant across sessions. In addition, coherence among units reflected timing of an expected visual stimulus change. These results suggest a more complex model of visual processing where topdown contextual information strongly and continuously influences stimulus-specific bottom-up processes at even the earliest stages of visual processing.
Much of what we know about visual processing in the brain is based on neural data collected in anesthetized animals assuming that the essential aspects of the computations are preserved under such conditions. However, recent findings support an alternative view that visual processing depends upon ongoing activity, which is significantly altered in anesthetized preparations. Therefore, it is critical to assess how well the characteristics of neural responses to various stimuli in the anesthetized animal can predict responses in the awake animal. We collected multi-electrode recordings from the primary visual cortex of adult rats under different levels of anesthesia and while awake. Anesthesia was maintained by isoflourane concentrations between 0.6% to 2.0%, ranging from very lightly anesthetized to deeply anesthetized. Isolated unit and local field potential (LFP) activity were collected from sixteen electrodes. Responses were compared between conditions of darkness (the spontaneous condition), a natural scene movie, and full-field white-black modulation at frequencies of 1Hz, 2Hz, 4Hz, and 8Hz. There were significant, up to two-fold modulations of measurements of average firing rates, bursting rates, power spectral densities, population sparseness, and coherence between stimulus conditions in awake and anesthetized animals. However, there were strong interactions between the particular stimuli used and the condition of the animal, and due to these interactions responses in the awake condition could not be well predicted by the anesthetized responses. While, in general, coherence decreased with lower concentrations of isoflurane as suggested by previous findings, coherence in the theta band actually peaked at 4 Hz visual stimulus modulation while awake, and that coherence in the gamma and alpha bands reached a minimum at 1-2Hz stimulation while under anesthesia. We suggest that anesthesia selectively modulates the neural dynamics in the cortex, and thus the patterns of visually-evoked responses in the awake animal and under anesthesia are not related to each other in a straightforward manner.
According to recently emerging views on visual cortical processing, activity in the primary visual cortex is governed by dynamically changing internal states of the system modulated by the incoming information rather than being fully determined by the visual stimulus. We analyzed systematically the dynamical nature of these states and the conditions required for their emergence. Multi-electrode recordings in the primary visual cortex of awake behaving ferrets (N=30) were analyzed after normal and visually deprived development at different ages spanning the range between postnatal day (P) 24 and P170. Visual deprivation has been achieved by bilateral lid suture up to the time of the visual tests. Multi-unit recordings were obtained in three different conditions: in the dark, while the animals watched random noise sequences, and while they saw a natural movie. 10-second segments of continuous recordings under these conditions were used to train two alternative state-dependent models, one based on Hidden Markov modeling that assumes internal dynamical dependencies among subsequent internal states and the other based on Independent Component Analysis which does not assume such dependencies. HMM significantly outperformed ICA (p<0.001) for both normal and lid sutured animals. In addition, HMM performance increased with age (p<0.001), more so than ICA did (p<0.001). We also assessed the similarity between different underlying states across different conditions (Movie, Noise and Dark), by computing the Kullback-Leibler distance between the probability distribution of the observed population activity generated by the underlying states. We found that, in general, similarity between underlying states across conditions strongly increased with age for normal animals, but this similarity remained significantly lower than that for lid sutured animals (p<0.0001). In addition, the number of transitions in the oldest age group was higher in normal animals compared to lid sutured ones (p<0.001). The result suggests that positing dynamic underlying states that emerge with age and can capture the behavior of cell assemblies is critical in characterizing the neural activity in the primary visual cortex. However, both the behavior and the emergence of these states depend only partially on proper visual input, and it is determined to a large extent by internal processes.
2007
Images presented at fixation provide more information to the visual system than images presented parafoveally. However, it is not clear whether it is more beneficial to receive the larger amount of information first in sequential categorical comparisons. Theories based on activation of mental sets, pure information content, or interference make different predictions on the likely outcomes of such tasks. In our study, subjects made same-different category judgments on a large set of briefly appearing pairs of grayscale images of everyday objects, which were presented on a gray background. Each image extended 5 degrees of visual angle, could appear in either the center (C) or corners (S) of the screen for 12.5, 25, or 50 msec, and was followed by a random mask presented for 25 msec. Pairings of position, timing, and category were fully randomized and balanced across trials, and the ISI between the two images within a trial was kept at 12.5msec. Subjects were instructed to fixate at the center of the screen, and their eye movements were monitored. There was a significant advantage in conditions where the central image appeared first and the peripheral image second (C-S) compared to the opposite order (S-C) (t(16)=0.02, p [[lt]] 0.05). However, the relation between stimulus presentation time and categorization performance in the C-S condition was non-monotonic: longer duration was not always paired with better performance. These results rule out pure information-based explanations and suggest that object information received earlier constrains how efficiently information received subsequently is processed in categorization tasks.
The accurate representation of local contour orientation is crucial for object perception, yet little is known about how humans encode this information while viewing complex images. Using a novel image manipulation method, we assessed sensitivity to the local orientation structure of natural images of differing complexity. We found that the visual system involuntarily discounts substantial levels of orientation noise until it exceeds levels that are considerably higher than the smallest orientation change that can be discriminated for a single contour. The much higher threshold and a characteristic dipper function we observe do not fit the classic view of orientation processing, but can be readily explained by a higher-level template-based process that provides an a priori reference for the expected form of objects.
Much of what we know about visual processing in the brain is based on neural data collected in anesthetized animals assuming that the essential aspects of the computations are preserved under such conditions. However, recent findings support an alternative view on visual perception that puts a strong emphasis on the role of ongoing activity which is all but eliminated in anesthetized preparations. According to this view, spontaneous activity represents momentary biases, contextual information and internal states of the brain that are essential for interpreting the incoming sensory information. Thus it is critical to understand what aspects of spontaneous activity carry relevant information for perception. To study this question, we collected and analyzed multi-electrode recordings in the primary visual cortex of adult rats under different levels of anesthesia. Anesthesia was induced by isoflourane ranging from 1.0 to 3.0% in increments of 0.5%. Isolated unit and local field potential (LFP) activity was collected from sixteen electrodes. Coherence analysis on LFPs revealed a clear increase from low to high levels of isoflurane anesthesia. Specifically, the mean coherence between electrodes over the LFP frequency range decreased with each increase in isoflurane concentration, from 1.0% to 3.0%. Variation about the mean also increased with higher levels of anesthesia. In addition, peaks in correlation were broader under light levels of anesthesia than under deep levels. Therefore, isoflurane anesthesia seems not only to reduce overall levels of cortical activity, but also to decrease the amount of correlation and coherence in ongoing activity. These results suggest that ongoing activity in the primary visual cortex of the rat has a structure that is appropriate for conveying relevant information for visual processing. In contrast to the presently dominant feed-forward view on perceptual processing, using this information requires a rapid dynamic integration of bottom-up an top-down signals in the primary visual cortex.
The dominant view on how humans develop new visual representations is based on the paradigm of iterative associative learning. According to this account, new features are developed based on the strength of the pair-wise correlations between sub-elements, and complex features are learned by recursively associating already obtained features. In addition, Hebbian mechanisms of synaptic plasticity seem to provide a natural neural substrate for associative learning. However, this account has two major shortcomings. First, in associative learning, even the most complex features are extracted solely on the basis of pair-wise correlations between their sub-elements, while it is conceivable that there are features for which higher order statistics are necessary to learn. Second, learning about all pair-wise correlations can already be intractable since the storage requirement for such representations grows exponentially with the number of elements in a scene, and learning progressively higher order statistics only exacerbates this combinatorial explosion. We present the results of a series of experiments that assessed how humans learn about higher-order statistics. We found that learning in an unsupervised visual task is above chance even when pair-wise statistics contain no relevant information. We implemented a formal normative model of learning to group elements into features based on statistical contingencies using Bayesian model comparison, and demonstrate that humans perform close to Bayes-optimal. Although the computational requirements of learning based on model comparison are considerable, they are not incompatible with Hebbian plasticity, and offer a principled solution to the storage-requirement problem by generating optimally economical representations. The close fit of the model to human performance in a large set of experiments suggests that humans learn new complex information by generating the simplest sufficient representation based on previous experience and not by encoding the full correlational structure of the input.
In this talk, we focus on two puzzles coming from two lines of research. First, cortical neurons show high level of spontaneous activity. The role of this metabologically expensive and richly structured ongoing neural signal with strong stimulus independent variance is presently unknown. Second, previous theoretical approaches proposed that neural activity in the primary visual cortex can be explained by a formal computational goal: cells in V1 are optimized for providing a sparse but complete and efficient representation of the structure of natural scene stimuli. According to the proposal, this efficient code for statistical estimates of natural scene stimuli would be learned via unsupervised learning using a set of natural image patches as stimuli. However, these codes can give an account for only the mean responses of cells obtained by averaging across multiple presentations of the same stimuli. Therefore, such codes generate correct responses only to a limited number of bar stimuli and they cannot explain any of the rich repertoire of responses to more complex stimuli. Neither can they clarify the within-trial variability observed in cells. Our proposal consists of two parts. First, we suggest that ongoing activity and the variance observed in the responses of cortical neurons to stimuli is not mere noise but contributes to the more faithful representation of the stimulus. Second, we propose that neural activity encodes not just the most probable single interpretation of the stimulus but also its uncertainty in the form of a probability distribution over possible interpretations. We explored the idea that activity in V1 reflects sampling of the recognition distribution, the probability distribution of possible hypotheses that are congruent with both the present and past inputs to the system. We also used this sampled approximation to the true recognition distribution in a variant of the expectation-maximization algorithm in an unsupervised learning scheme to adapt the synaptic weights between cells so that they form the efficient code postulated by earlier studies. This learning scheme reproduced the linear filter properties of simple cells, just like the previous studies did. However, our results can also account for several properties of V1 receptive fields such as non-classical behaviors of receptive field without the need of using extra lateral connections or divisive gain control mechanisms.
Previous theoretical approaches relating neural activity in the primary visual cortex to formal computational goals that V1 might be optimized for focused mostly on the filter-like properties of cells or on related features such as contrast invariance. The key insights gained from these studies were that V1 neurons (simple cells, in particular) can be seen as implementing an efficient code for statistical estimates of natural scene stimuli and that this code can be learned from a set of natural image patches. However, this approach only accounts for the mean responses of cells averaged across multiple presentations of the same (set of) stimuli, and therefore completely neglects the rich within-trial dynamical interactions between cells. For the same reason, it is also incapable of accounting for the richly structured spontaneous activity in V1. In order to better understand the relation of the intrinsic dynamics of V1 to its computational role, we explored the idea that activity in V1 reflects sampling of the ‘recognition distribution’, the probability distribution of possible hypotheses that are congruent with both the present and past inputs to the system. We also used this sampled approximation to the true recognition distribution in a variant of the expectation-maximization algorithm to adapt the synaptic weights between cells so that they form the efficient code hypothesized in earlier work. Beyond reproducing the linear filter properties of simple cells, our results also account for temporal and spatial correlations between cells as seen in multielectrode recordings, and give a normative account of the experimentally observed close correspondence between spontaneous and stimulus-driven network activity in V1.